Go工程化实践之工程项目结构
标准Go项目结构
Standard Go Project Layout
当一个项目需要更多的人参与进来,项目比较复杂,那么这个项目就需要更多的结构,包括需要一个 toolkit 来方便生成项目的模板,尽可能大家统一的工程目录布局。(比如 go-micro、go-zero、kratos)
目录
/cmd本项目的主干
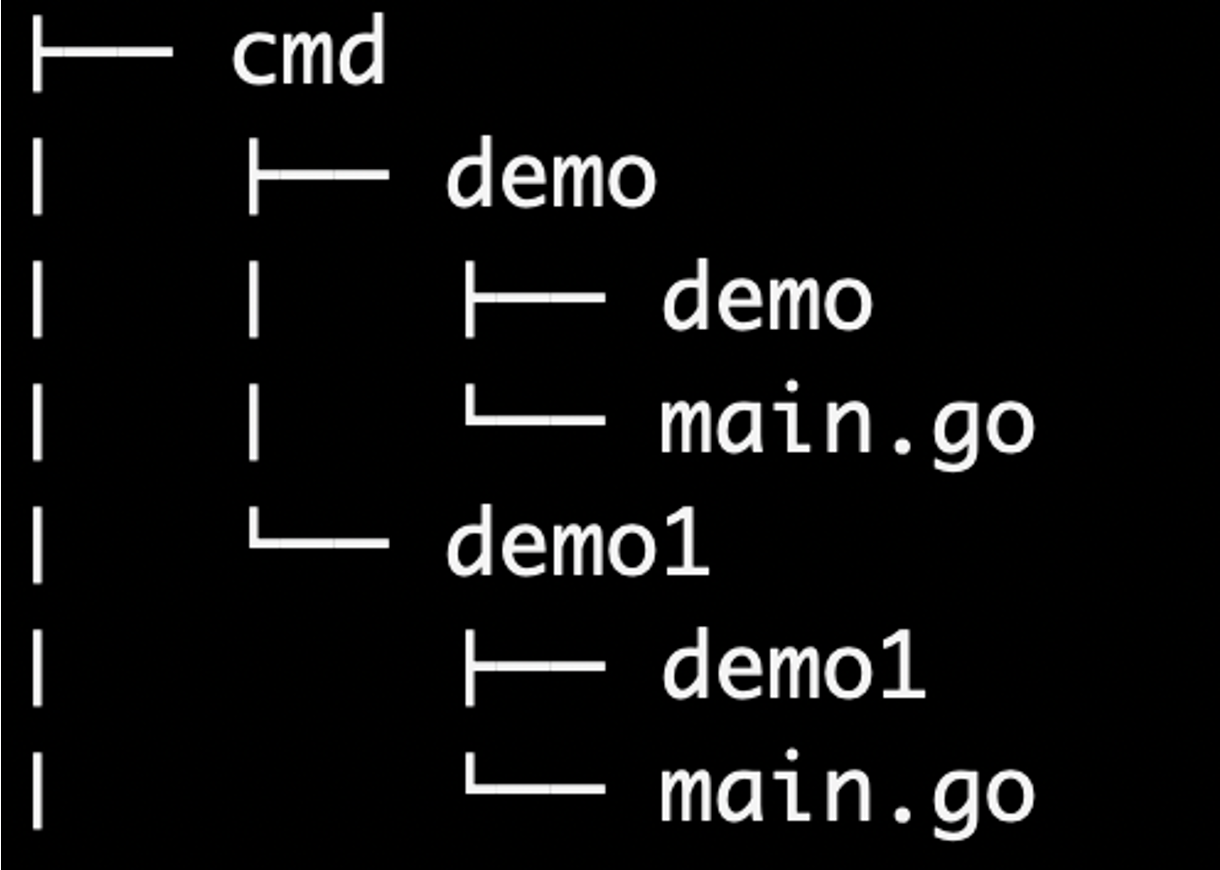
每个应用程序的目录名应该与你想要的可执行的名称相匹配(例如
/cmd/myapp)。不要在这个目录中放置太多代码,如果你认为代码可以导入并在其他项目中是哟跟,那么他应该位于
/pkg目录中。如果代码不是可重用的,或者你不希望其他人重用它,请将该代码放到/internal目录中。![image-20230925113455115]()
/internal私有应用程序和库代码。这是你不希望其他人在应用程序或库中导入代码。
请注意,这个布局模式是由 Go 编译器本身执行的。有关更多细节,请参阅 Go 1.4 release nodes。注意,你并不局限于顶级
internal目录。在项目树的任何级别上都可以有多个内部目录。你可以选择向
internal包中添加一些额外的结构,以分隔共享和非共享的内部代码。这不是必须的(特别是对于较小的项目),但是最好有可视化的线索来显示预期的包的用途。你的实际应用程序代码可以放在
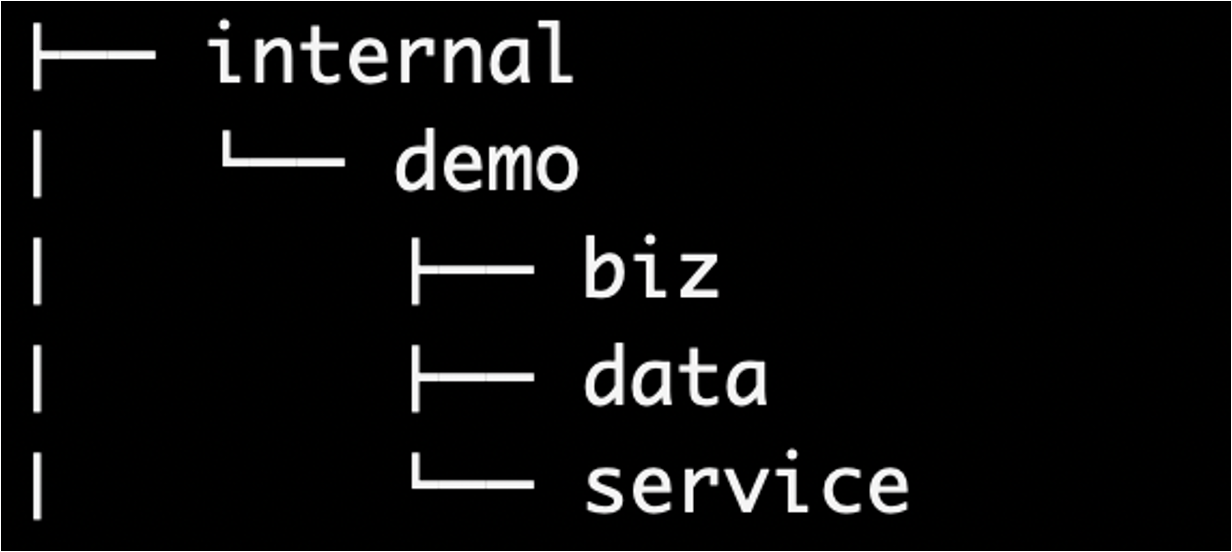
/internal/app目录下(例如/internal/app/myappp),这些应用程序共享的代码可以放在/internal/pkg目录下(例如/internal/pkg/myprivlib)。因为我们习惯吧相关的服务,比如账号服务,内部有
rpc、job、admin等,相关的服务整合一起后,需要区分app,单一的服务,可以去掉/internal/myapp。(这里注意,一个代码线上,有很多个微服务,而且这些微服务之间,是通过rpc等方式跨进程请求交互。。)![image-20230925114820947]()
/pkg外部应用程序可以使用的库代码(例如
/pkg/mypubliclib)。其他项目会导入这些库,所以在这里放东西之前要三思。注意:
internal目录是确保私有包不可导入的更好方法,因为它是由 Go 强制执行的。/pkg目录仍然是一种很好的方式,可以显式地表达该目录中的代码对于其他人来说是安全使用的好方法。/pkg目录内,可以参考 go 标准库的组织方式,按照功能分类。/internal/pkg一般用于项目内的跨多个应用的公共共享代码,但其作用域仅在单个项目工程内。由 Travis Jeffery 撰写的
I'll take pkg over internal博客文章提供了pkg和internal目录的一个很好的概述,以及什么时候使用它们是有意义的。当根目录包含大量非 Go 组件和目录时,这也是一种将 Go 代码分组到一个位置的方法,这使得运行各种 Go 工具变的更加容易组织。
![image-20230925114820947]()
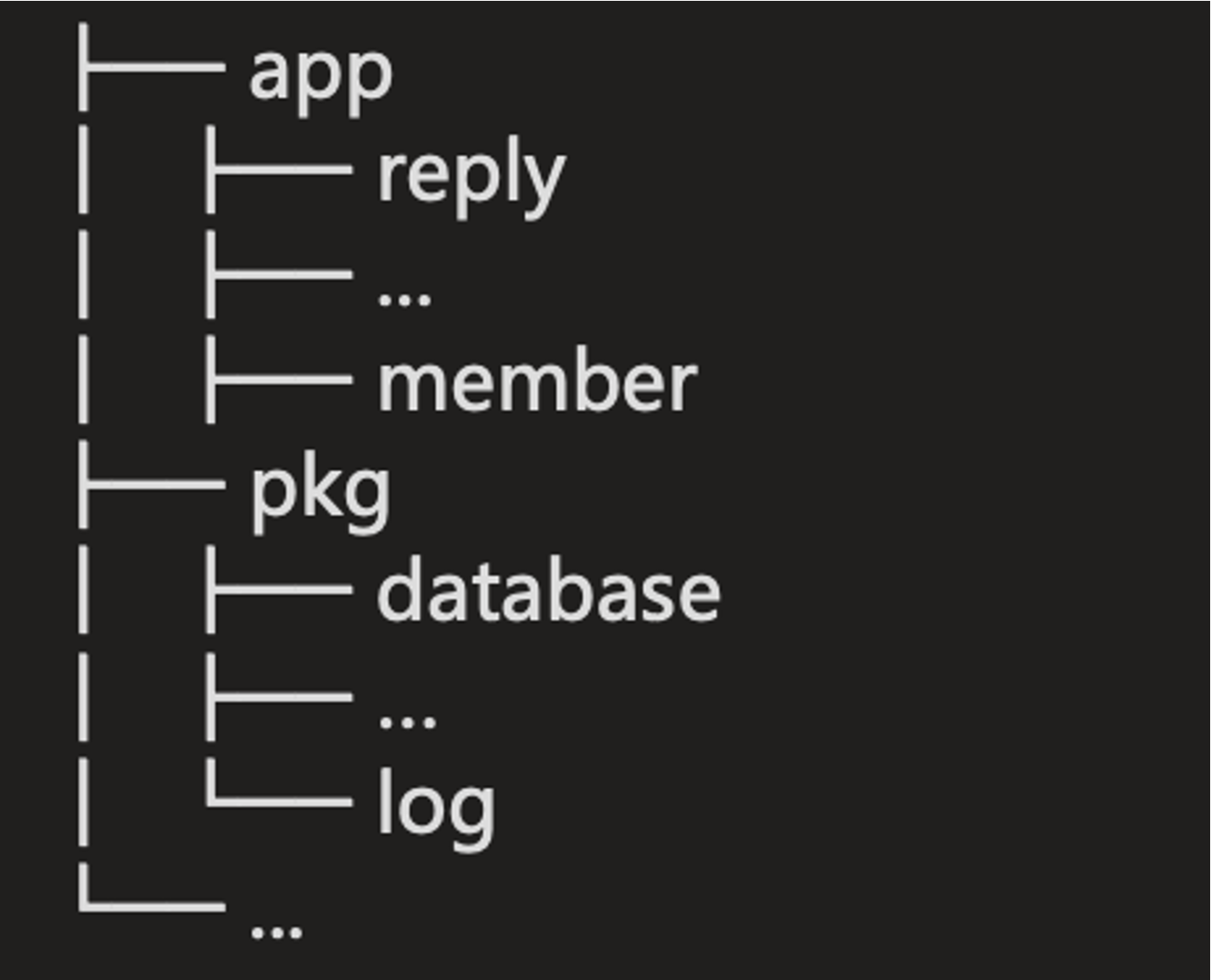
其他目录
![image-20230925115030312]()


工具包
Kit Project Layout
每个公司都应当为不同的微服务建立一个统一的 kit 工具包项目(基础库/框架)和 app 项目。
基础库 kit 为独立项目,公司级建议只有一个,按照功能目录来拆分会带来不少的管理工作,因此建议合并整合。
Package Oriented Design
To this end, the
Kitproject is not allowed to have a vendor folder. If any of packages are dependent on 3rd party packages, they must always build against the latest version of those dependences.为此,
Kit项目不允许有vendor文件夹。如果软件包依赖于第三方软件包,则必须始终根据这些依赖包的最新版本进行构建。
kit 项目必须具备的特点:
- 统一
- 标准库方式布局
- 高度抽象
- 支持插件
服务端应用程序布局
Service Application Project Layout
/apiAPI 协议定义目录,
xxapi.protoprotobuf文件,以及生成的go文件。我们通常把api文档直接在proto文件中描述。/configs配置文件模板或默认配置
/test额外的外部测试应用程序和测试数据。可以随时根据需求构造
/test目录。对于较大的项目,有一个数据子目录是有意义的。例如,你可以使用/test/data或/test/testdata(如果你需要忽略目录中的内容)。请注意,Go 还会忽略以.或_开头的目录或文件,因此在如何命名测试数据目录方面有更大的灵活性。不应该包含
/src有些 Go 项目确实有一个
src文件夹,但这通常发生在开发人员有Java北京,在那里它是一种常见的模式。不要将项目级别src目录与Go用于其工作空间的src目录。
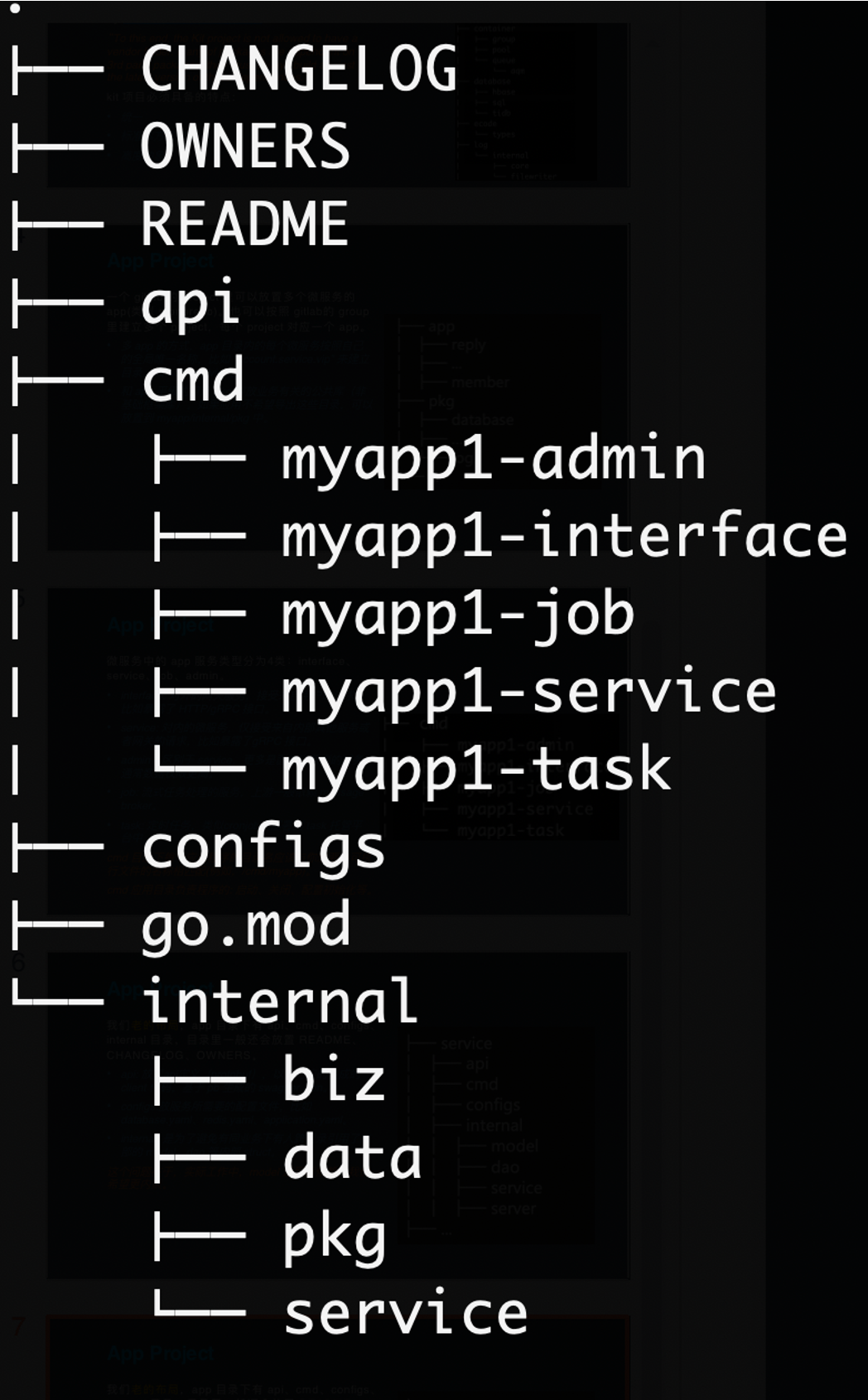
一个 gitlab 的 project 里可以放置多个微服务的 app(类似 monorepo)。也可以按照 gitlab 的 group 里建立多个 project,每个 project 对应一个 app。
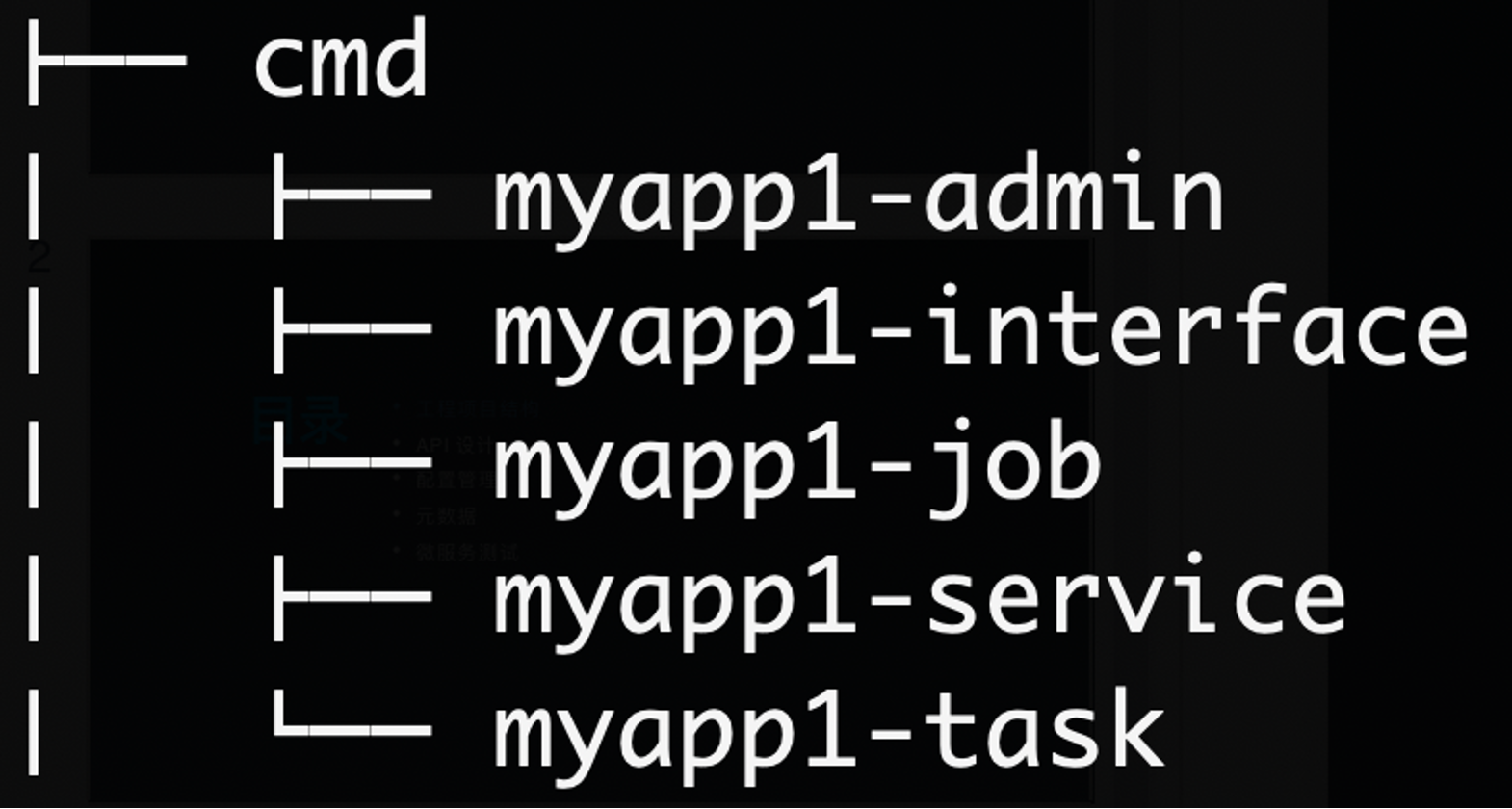
- 多
app的方式,app目录内的每个微服务按照自己的全局唯一名称,比如account.service.vip来建立目录,如:account/vip/* - 和
app平级的目录pkg存放业务有关的公共库(非基础框架库)。如果应用不希望导出这些目录,可以放置到myapp/internal/pkg中。
微服务中的 app 服务类型分为4类:interface、service、job、admin
interface:对外的BFF服务,接受来自用户的请求,比如暴露了HTTP/gRPC接口service:对内的微服务,仅接受来自内部其他服务或者网关的请求,比如暴露了gRPC接口只对内服务admin:区别于service,更多是面向运营侧的服务,通常数据权限更高,隔离带来更好的代码级别安全。job:流式任务处理的服务,上游一般依赖message brokertask:定时任务,类似cronjob,部署到task托管平台中。
cmd 应用目录负责程序的:启动、关闭、配置初始化等。
服务端应用目录层级划分-v1
在老布局里面,app 目录下有 api 、cmd、configs、internal 目录,目录里一般还会放置 README、CHANGELOG、OWNERS。
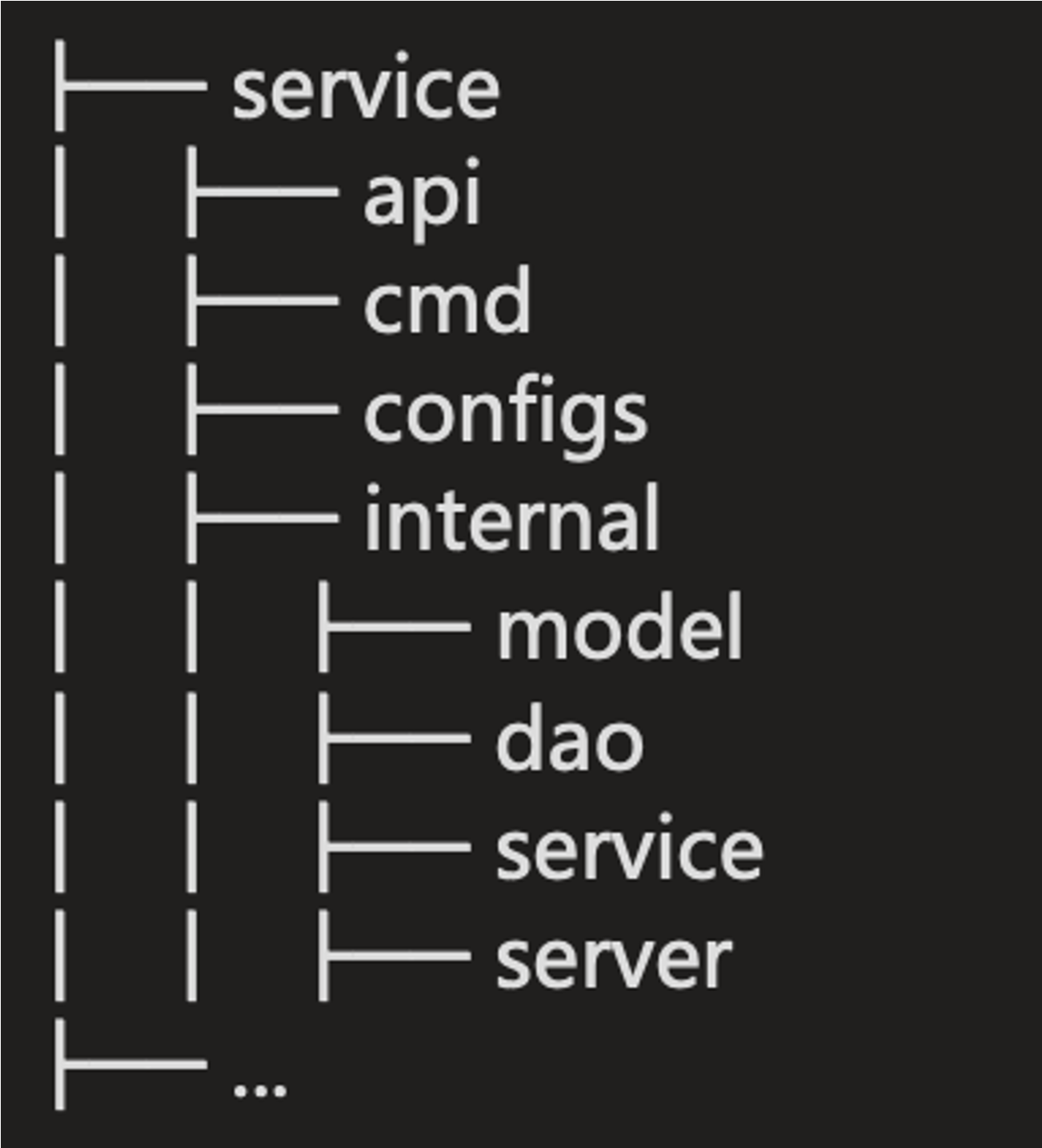
api:放置 API 定义(protobuf),以及对应的生成的client代码,基于pb生成的swagger.jsonconfigs:方服务所需要的配置文件,比如database.yaml,redis.yaml,application.yamlinternal:是为了避免有同业务下有人跨目录引用了内部的model、dao等内部structserver:放置HTTP/gRPC的路由代码,以及DTO转换的代码
DTO(Data Transfer Object):数据传输对象,这个概念来源于 J2EE 的设计模式。但在这里,泛指用于展示层、 API 层于服务层(业务逻辑层)之间的数据传输对象。
项目的依赖路径为:model <- dao -> service -> api,model struct 串联各个层,直到 api 需要做 DTO 对象转换。
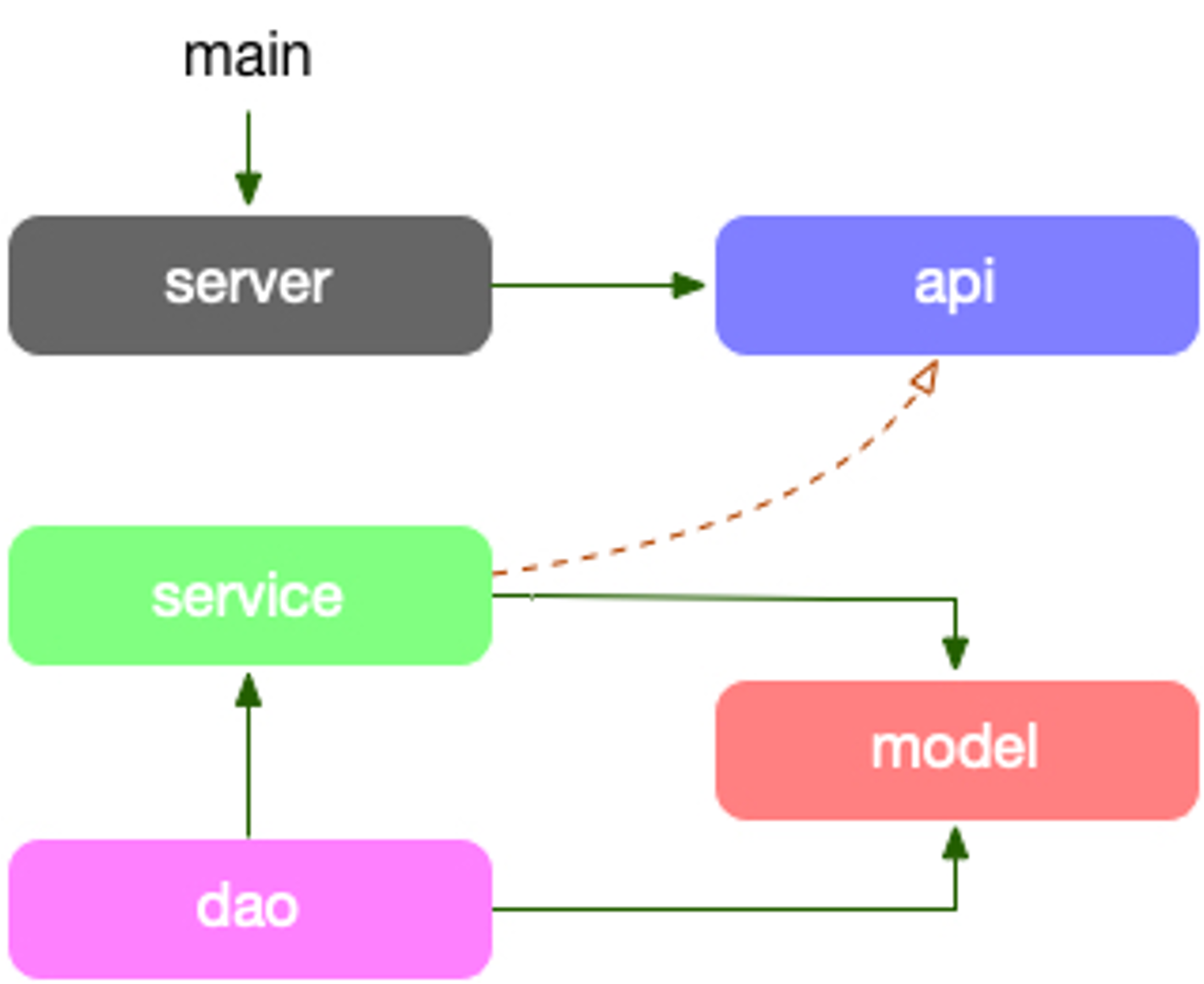
model:放对应“存储层”的结构体,是对存储的一一映射dao:数据读写层,数据库和缓存全部在这层统一处理,包括cache miss处理service:组合各种数据访问来构建业务逻辑server:依赖proto定义的服务作为入参,提供快捷的启动服务全局方法api:定义了 APIproto文件,和生成的stub代码,它生成的interface,其实现者在service中。
service 的方法签名因为实现了 API 的接口定义,DTO 在业务逻辑层直接使用了,更有 dao 直接使用,最简化代码。
DO(Domain Object):领域对象,就是从现实世界中抽象出来的有形或无形的业务实体(是一个面向业务的结构体,例如需要返回给上层使用的结构体)。缺乏 DTO -> DO 的对象转换。
服务端应用目录层级划分-v2
app目录下有 api、configs、internal 目录,目录里一般还会放置 README、CHANGELOG、OWNERS
internal:是为了避免有同业务下有人跨目录引用了内部的biz、data、service等内部structbiz:业务逻辑的组装层,类似 DDD 的domain层,data类似 DDD 的repo,repo接口在这里定义,使用 依赖倒置 的原则。包含领域对象,将这个领域对象作为实现业务逻辑的主体。data:业务数据访问,包含cache、db等封装,实现了biz的repo接口。我们可能会把data与dao混淆在一起,data偏重业务的含义,他所要做的是将领域对象重新拿出来,我们去掉了DDD的infra层。service:实现了api定义的服务层,类似DDD的application层,处理DTO到biz领域实体的转换(DTO -> DO),同时协同各类biz交互,但是不应处理复杂逻辑。
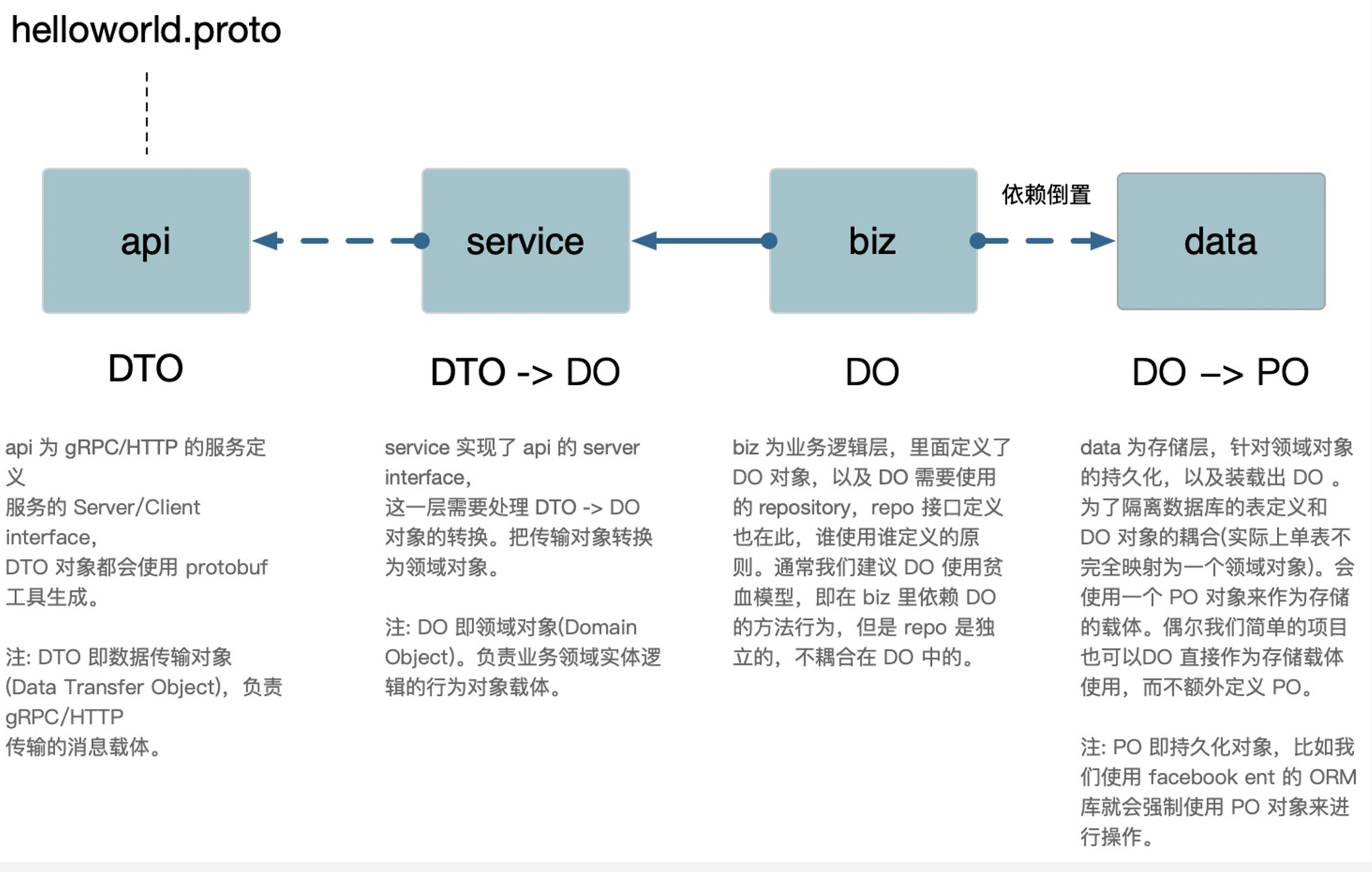
PO(Persistent Object):持久化对象,它跟持久层(通常是关系型数据库的数据结构,形成一一对应的映射关系,如果持久层是关系型数据库,那么数据表中的每个字段(或若干个)就对应 PO 的一个(或若干个)属性。
如果将 DDD 设计中的一些思想和工程结构做一些简化,映射到 api、service、biz、data 各层
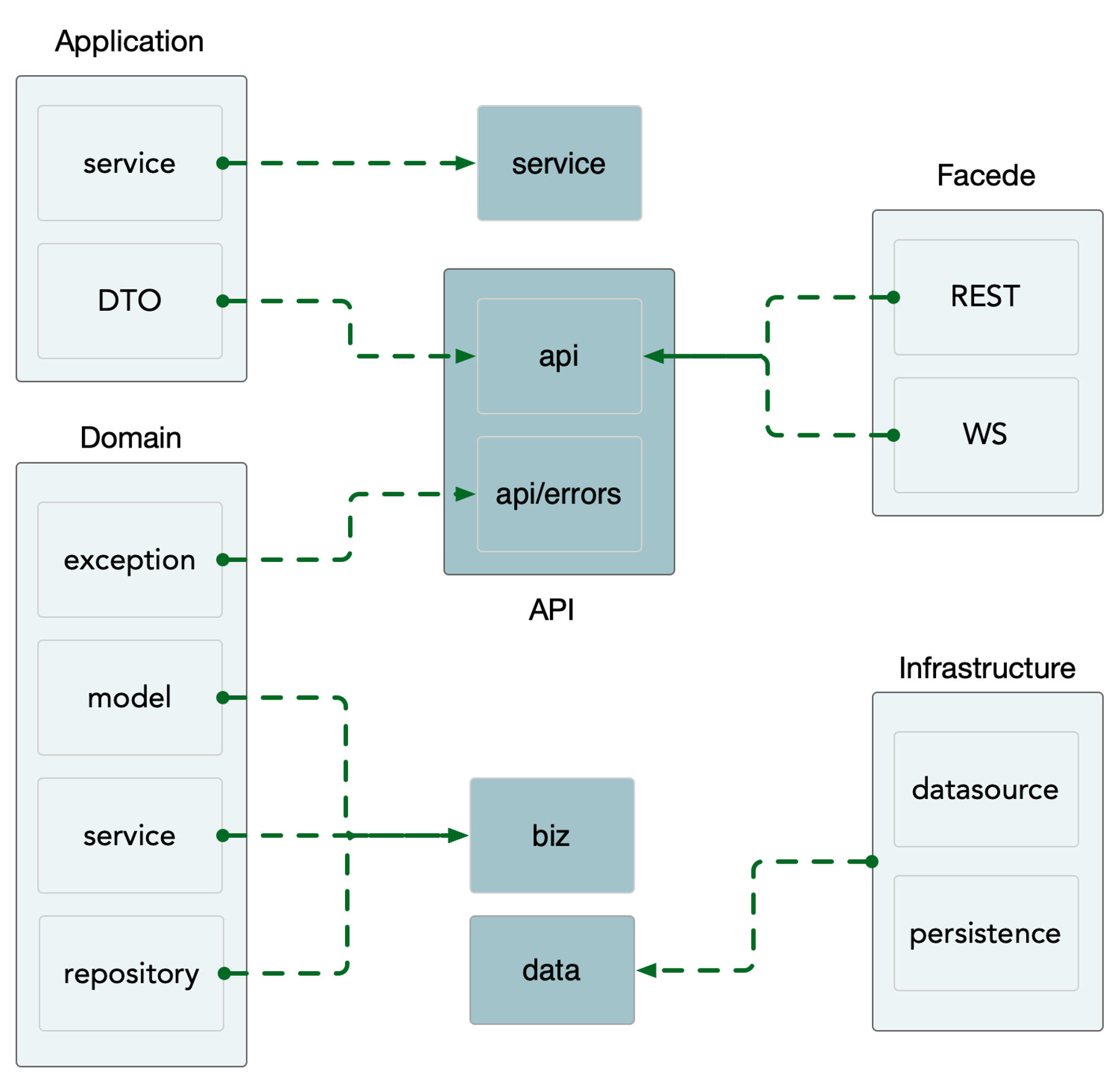
松散分层架构( Relaxed Layout System)
层间关系不那么严格。每层都可以使用它下面所有层的服务,而不仅仅是下一层的服务。每层都可能是半透明的,这意味着有些服务只对上一层可见,而有些服务对上面的所有层都可见。
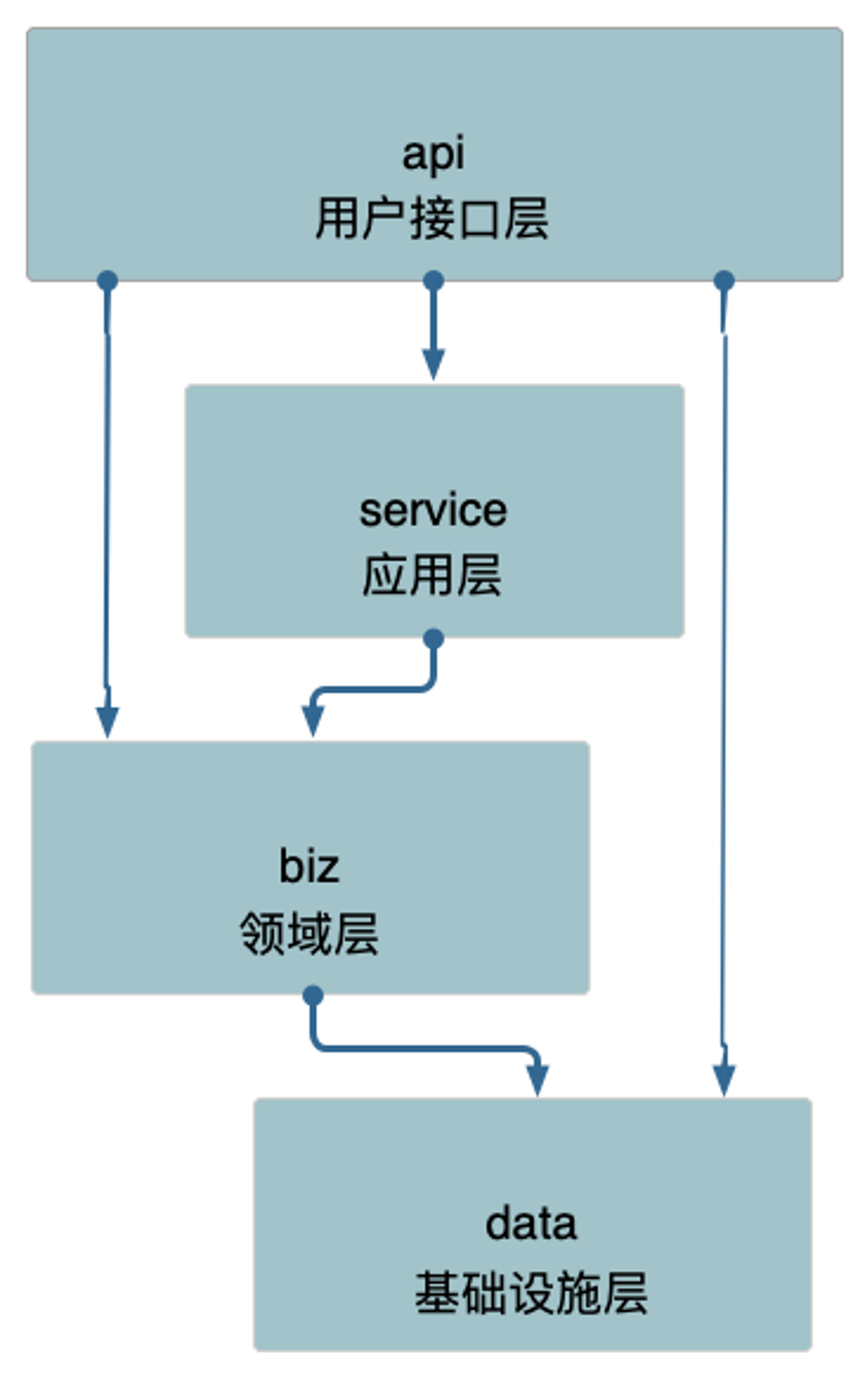
同时在领域驱动设计(DDD)中也采用了继承分层架构(Layering Through Inheritance),高层继承并实现低层接口。
调整一下各层的顺序,并且将基础设施层移动到最高层。
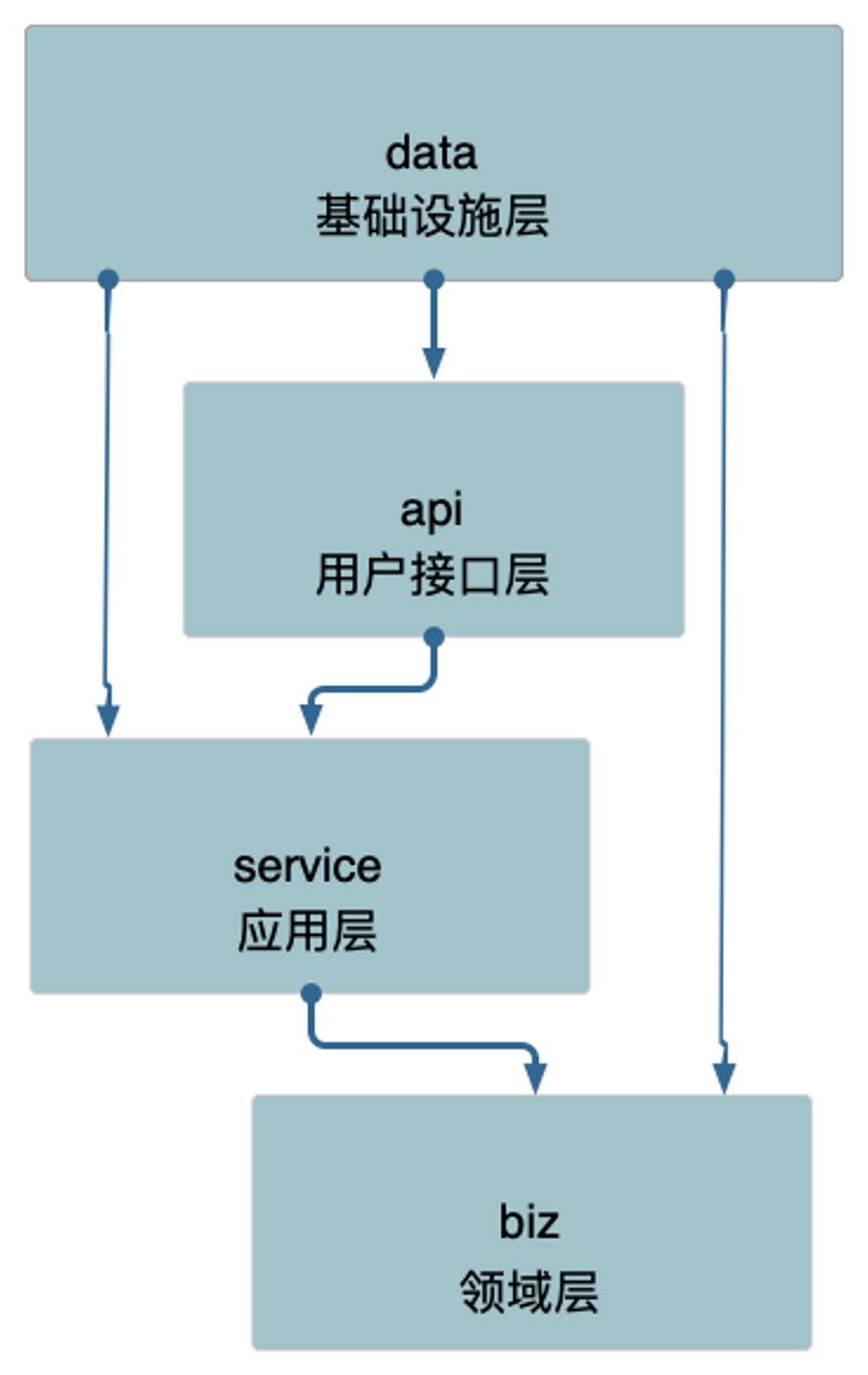
注意:继承分层架构依然是单相依赖,这也意味着领域层、应用层、表现层能不将依赖基础设施层,相反基础设施层可以依赖它们。
失血模型与充血模型
在这里,可以理解为:
失血模型:model 中的 struct 只有纯数据结构,所有的业务逻辑(例如 getter/setter)由 service 层完成
贫血模型:struct 带有一部分属性判断逻辑,在 service 层可以直接调用使用,不包含依赖持久层的业务逻辑。这部分依赖于持久层的业务逻辑将会放到服务层中。可以看出。贫血模型中的领域对象是不依赖于持久层的。
充血模型:充血模型中包含了所有的业务逻辑,闹括依赖于持久层的业务逻辑。所以,使用充血模型的领域层是依赖于持久层,简单表示就是 UI层 -> 服务层 -> 领域层 -> 持久层。
胀血模型:胀血模型就是把和业务逻辑不相关的其他应用逻辑(如授权、事务等),都放在领域模型中。比较臃肿,服务层小时,领域层干了服务层的事,相对服务层而言,服务层变成失血模型。
ent - 一个强大的Go语言实体框架
经济适用版项目布局 - 单体应用
如果写一个简单的单体服务,不需要参杂多个服务作为微服务形式,可以采用更加简单的项目布局
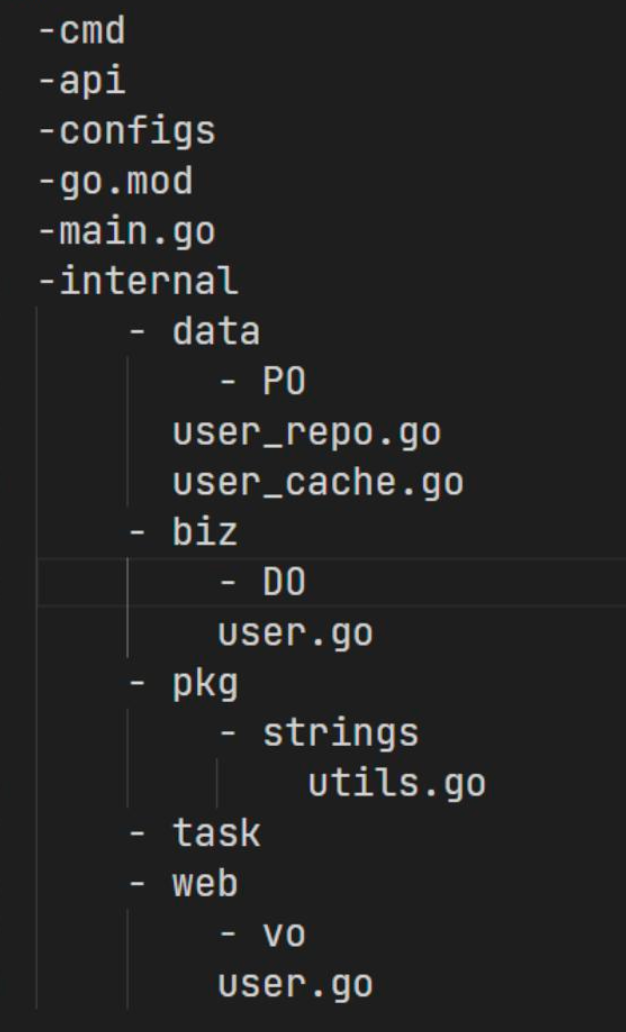
可以考虑替换的:
data里面放的是PO,也可以改名叫作model- 在业务逻辑不复杂的情况下,
DO和PO可以只保留一个。也就是,在这种场景下,也可以改名叫作 model。它会被直接用于持久化,以及承担 轻量的 业务逻辑 - 如果要承担很多逻辑,最好将DO分离出来 pkg里面放各种通用的、与业务无关的代码web直接暴露HTTP接口。它主要调用biz的方法来完成业务逻辑,而后将数据转换成VO暴露出去。VO建议保留,因为页面的需求是千变万化的,但是model之类的是很稳定的。web和task都依赖于biz。task提供一些定时或者周期任务cmd也尽量依赖于biz,相当于只是将业务逻辑暴露为简单的命令行pkg里面绝对不能依赖任何别的包(因为可以在多个项目中使用,例如可以 雪花算法id生成器、切片去重等处理)
如果单体应用内容较多,则可以再通过目录细化出来
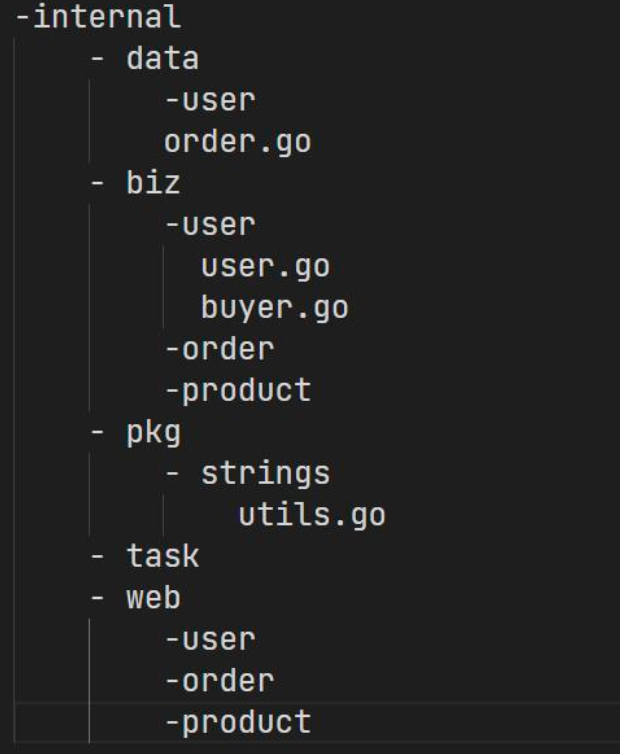
web、biz、data、task都进一步按照业务进一步划分;- 不必每一部分都直接全部分到最细,比如说
data里面user部分很多内容,就单独一个文件夹放着,但是其他部分不多,就直接放在data下,将来再考虑拆分; - 在按照业务细分之后,可以考虑使用集中的
VO目录,也可以直接定义在各自的业务文件夹下。例如user的VO可以直接放在/web/user里面,也可以有一个/web/vo。biz和data也是类似处理;
拆分
如果目录结构演化到比较复杂的底部,那么只需要将某个业务的全部层级里面的代码拆出来,挪到一个新的项目就可以。
例如同目录下文件非常多
此时,可以将用户服务和订单服务拆开
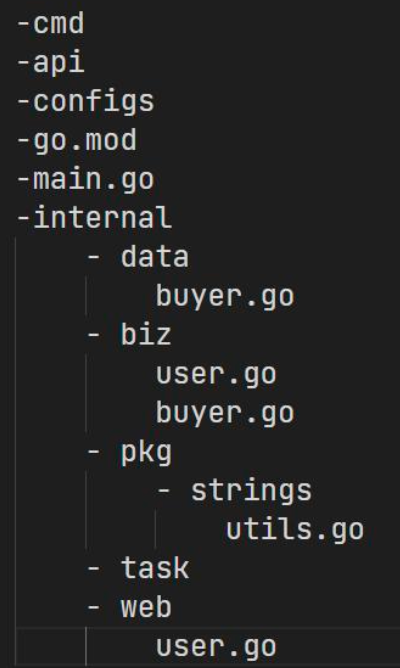
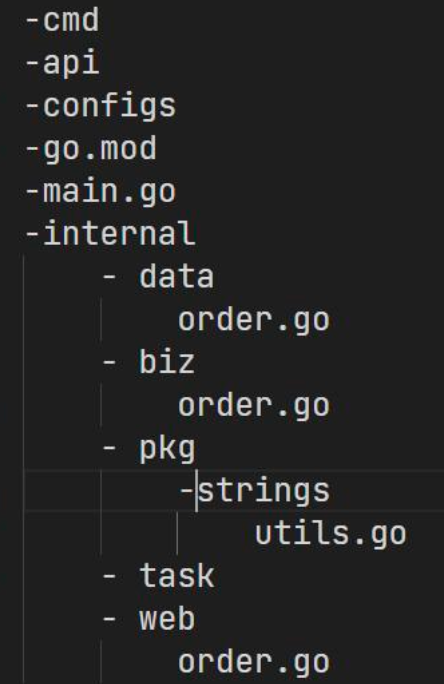
将 pkg 复制两份即可
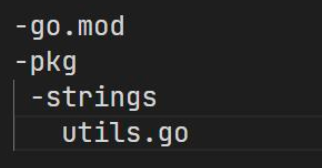
按照 BFF 分层的话,还可以拆分出一个 web 应用和多个领域服务,以及可能的一个 kit
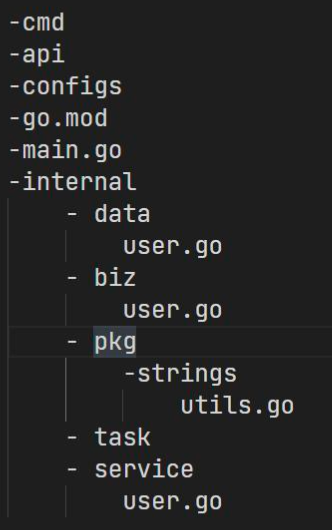
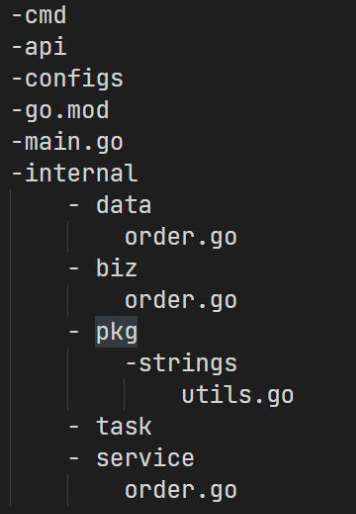
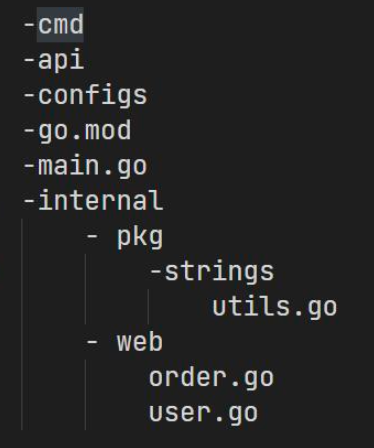
服务拆分的思路
核心原则:高内聚,低耦合
- 横向按照层级分,或者说按照功能分:如
service,biz,data。这种划分有很明显的层级结构 - 竖向按照业务分
那么,按照横向分或者竖向分的原则:
- 因为业务复杂度演进而带来的,应该竖向分。典型例子是针对商家还是买家,细化用户服务
- 因为引入中间层级,尝试维系 内聚耦合 的,应该横向分。典型例子是在
data里面引入cache
一些简单粗暴的原则
- 需要被别的项目使用的代码,相当于是
pkg。因此被别的项目使用的代码要非常谨慎,因为pkg的代码丢过去就收不回来(类似于,一个大写开头的方法,暴露出去之后被调用,就无法改回来了) - 纯粹的微服务项目,
web项目,没啥代码在项目间复用的代码,全部丢过去internal - 额外的命令,比如说一些工具类命令,一些修复数据的命令,放在
cmd - 如果是中间件,除了是用户能用的接口、结构体,其他都放在
internal - 以公司规范为准,没有规范就以
v2版本为主。如果项目特别小,就是CRUD,可以裁剪一部分V2 - 甚至在单体应用中,可以将
internal目录也去掉,直接将内部目录暴露出来
Lifecycle
Lifecycle 需要考虑服务应用的对象初始化以及生命周期的管理,所有 HTTP/gRPC 依赖的前置资源初始化,包括 data、biz、service,之后再启动监听服务。使用 wire ,来管理所有资源的 依赖注入。控制反转的一种方式就是依赖注入。为何需要依赖注入?

前者:需要在初始化的过程中,通过变量创建 redis 对象。但是在测试的时候,就不方便使用,还是需要手动创建对象。
后者:先创建一个 redis 对象,然后在初始化的时候,使用这个对象。好处是在测试的时候,或者在其他模块,可以通过使用对象直接进行调用。
核心是为了:
- 方便测试
- 单词初始化和复用
使用依赖注入,可以方便的进行生命周期的管理。
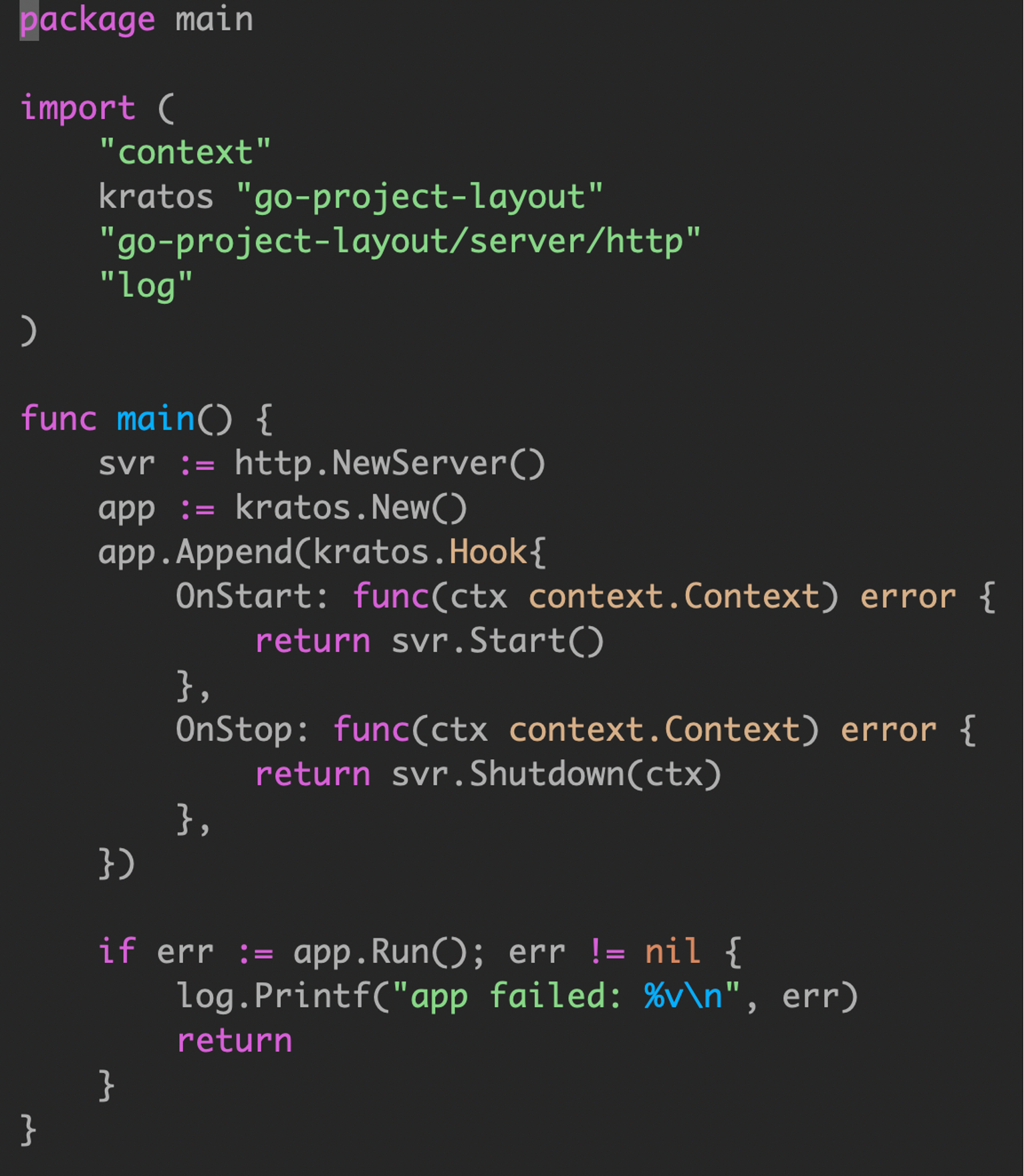
Wire
Compile-time Dependency Injection With Go Cloud’s Wire
wire
手撸资源的初始化和关闭是非常繁琐,容易出错的。上面提到我们使用依赖注入的思路 DI,结合 google wire,静态的 go generate 生成静态的代码,可以很方便和查看,不是在运行时利用 reflection 实现。
手动创建和初始化:


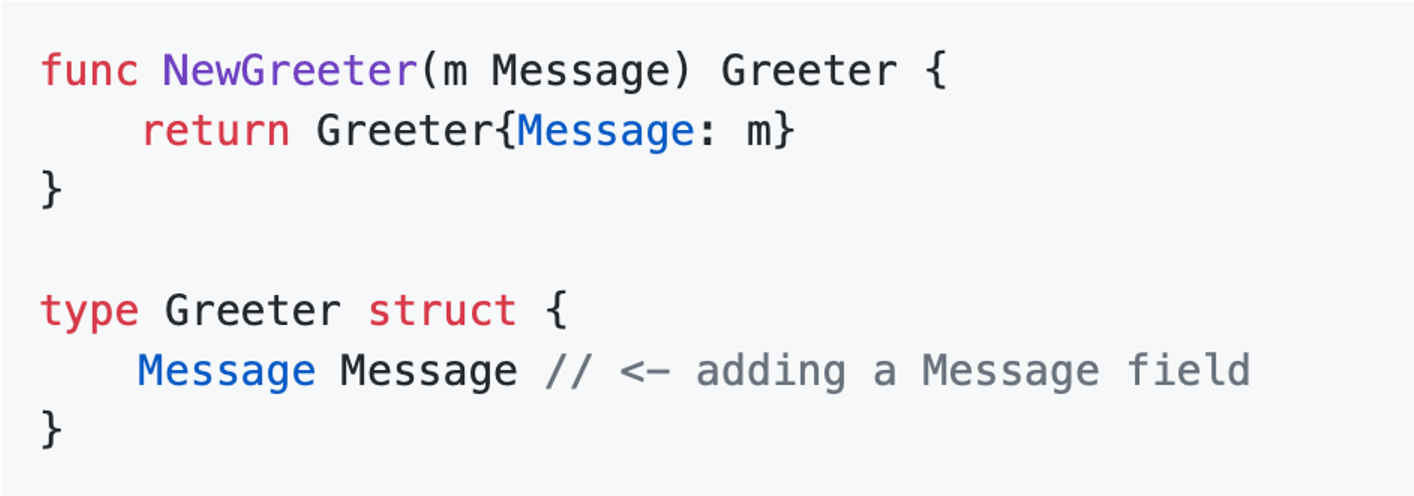


通过 wire 实现依赖注入

参考
Package Oriented Design
Design Philosophy On Packaging
Standard Go Project Layout
Standard Go Project Layout 中文
浅析VO、DTO、DO、PO的概念、区别和用处
阿里文娱技术专家战獒: 领域驱动设计详解之What, Why, How?
阿里技术专家详解 DDD 系列- Domain Primitive
阿里技术专家详解DDD系列 第二弹 - 应用架构
阿里技术专家详解DDD系列 第三讲 - Repository模式
贫血,充血模型的解释以及一些经验
领域驱动设计 实践手册(1.Get Started)
DDD 实践手册(2. 实现分层架构)
DDD 实践手册(3. Entity, Value Object)
DDD 实践手册(4. Aggregate — 聚合)
DDD 实践手册(5. Factory 与 Repository)
DDD 实践手册(6. Bounded Context - 限界上下文)
01、DDD和微服务的关系
Domain Driven Design in Go
Domain Driven Design in Go: Part 2
Domain Driven Design in Go: Part 3
当中台遇上DDD,我们该如何设计微服务?
领域驱动设计系列文章(1)——通过现实例子显示领域驱动设计的威力
领域驱动设计系列文章(2)——浅析VO、DTO、DO、PO的概念、区别和用处
领域驱动设计系列文章(3)——有选择性的使用领域驱动设计
The Clean Architecture
How Do You Structure Your Go Apps
zitryss/go-sample
Go 面向包的设计和架构分层
Clean Architecture using Golang
Trying Clean Architecture on Golang
Standard Package Layout
benbjohnson/wtf
Trying Clean Architecture on Golang
Trying Clean Architecture on Golang — 2
Applying The Clean Architecture to Go applications
Examples for my talk on structuring Go apps.
Ashley McNamara + Brian Ketelsen. Go best practices.
DTO to Entity Conversion in Java
I’ll take pkg over internal
Wire Best Practices
Wire User Guide
Compile-time Dependency Injection With Go Cloud’s Wire
Wire: Automated Initialization in Go