Kubernetes 控制平面组件:调度器和控制器
Scheduler
调度器,kube-scheduler 负责分配调度 Pod 到集群内的节点上,它监听 kube-apiserver,查询还未分配 Node 的 Pod,然后根据调度策略为这些 Pod 分配节点(更新 Pod 的 NodeName 字段)。
1 | kubectl get pod nginx-56fcf95486-p4dvd -o yaml |
调度器需要充分考虑诸多的因素:
- 公平调度
- 资源高效利用
- QoS
affinity和anti-affinity- 数据本地化(
data locality) - 内部负载干扰(
inter-workload interference) deadlines
调度器
kube-scheduler 调度分为两个阶段,predicate 和 priority:
predicate:过滤不符合条件的节点priority:优先级排序,选择优先级最高的节点(打分,将分数高的排在前面)
在插件式的 Kubernetes 里面,这两个阶段都是由多个插件进行组合。
Predicates 策略
一个一个插件运行,任何一个插件过滤掉,这个节点就被过滤。
PodFitHostPorts:检查是否有Host Ports冲突(当 Pod 直接使用主机的Port)PodFitsPorts:同PodFitsHostPortsPodFitsResources:检查Node的资源是否充足,包括允许的Pod数量、CPU、内存、GPU个数以及其他的OpaqueIntResources。HostName:检查pod.Spec.NodeName是否与候选节点一致(当指定 Pod 的运行节点)MatchNodeSelector:检查候选节点的pod.Spec.NodeSelector是否匹配NoVolumeZoneConflict:检查volume zone是否冲突MatchInterPodAffinity:检查是否匹配 Pod 的亲和性要求NoDiskConflict:检查是否存在Volume冲突,仅限于 GCE PD、AWS EBS、Ceph RBD 以及 iSCSIPodToleratesNodeTaints:检查Pod是否容忍Node TaintsCheckNodeMemoryPressure:检查Pod是否可以调度到MemoryPressure的节点上NoVolumeNodeConflict:检查节点是否满足Pod所引用的Volume的条件
还有很多其他策略,也可以编写自己的策略,用来过滤节点。
Predicates plugin 工作原理

一些节点的 list,在经过一些插件之后,过滤掉一些,最终剩下部分 Node。
Priorities 策略
不同的 plugin 都会有打分,最终的分会结合 plugin 的权重
SelectorSpreadPriority:优先减少节点上属于同一个Service或Replication Controller的Pod数量InterPodAffinityPriority:优先将Pod调度到相同的拓扑上(如同一个节点、Rack、Zone 等)(亲和性)LeastRequestedPriority:优先调度到请求资源少的节点上BalanceResourceAllocation:优先平衡各节点的资源使用NodePreferAvoidPodsPriority:alpha.kubernetes.io/preferAvoidPods字段判断,权重为 10000,避免其他优先级策略的影响NodeAffinityPriority:优先调度到匹配NodeAffinity的节点上TaintTolerationPriority:优先调度到匹配TaintToleration的节点上ServiceSpreadPriority:尽量将同一个service的Pod分布到不同节点上,已经被SelectorSpreadPriority替代(默认未使用)EqualPriority:将所有节点的优先级设置为 1 (默认未使用)ImageLocalityPriority:尽量将使用大镜像的容器调度到已经下拉了该镜像的节点上(默认未使用)MostRequestPriority:尽量调度到已经使用过的Node上,特别适用于cluster-autoscaler(默认未使用)
资源需求
查看 resources 字段解释
1 | kubectl explain pod.spec.containers.resources |
CPUrequests- Kubernetes 调度
Pod时,会判断当前节点正在运行的Pod的CPU Request的综合,再加上当前调度Pod的CPU request,计算其是否超过节点的CPU的可分配资源
- Kubernetes 调度
limits- 配置
cgroup以限制资源上限
- 配置
- 内存
requests- 判断节点的剩余内存是否满足
Pod的内存请求量,以确定是否可以将 Pod 调度到该节点
- 判断节点的剩余内存是否满足
limits- 配置
cgroup以限制资源上限
- 配置
申请资源的时候,不一定会直接全部使用 requests。不同的 QosClass 对调度的行为影响不一样。
查看节点资源
kubectl get node master -o yaml
1 | status: |
例如查看一个带有 resources 资源控制的字段的 Pod 的 docker 信息
1 | Containers: |
查看 docker 信息
1 | docker inspect 254f41a71b |
例如查看 CPU 在 cgroup 中的限制
1 | cd /sys/fs/cgroup/cpu/ |
cpu.shares:算法是Requests中的200/1000 * 1024=204。也就是有 0.2 个 CPU,1个 CPU 的时间分片是 1024 个。作用是当两个pod调度 CPU 的时候竞争,按照cpu.share分配时间片cpu.cfs_quota_us:用来控制访问CPU的绝对时间,结合cfs_period_us一起使用,100000微秒的时间片里面,可以使用100000微秒,就是 1,代表着使用上限就是 1 颗 CPUcfs_period_us:表示一个cpu带宽,单位为微妙,系统默认 100000
CPU 执行时如果没有超过该 CPU 上限,则直接使用,例如只有一个进程,占用 0.5 个 CPU,则 CPU 全部由这个进程调度;如果多个进程同时抢占调度一个 CPU,则通过 cpu.shares 来给三个进程分配时间片。
针对不了解具体需要有多少资源,但是又不希望不限制资源的情况,可以使用 LimitRange
1 | kubectl explain limitrange.spec.limits |
LimitRange 在命名空间中为每种资源设置资源使用限制。(即使是 init container 里面也一样,可能由于 init container 资源被限制导致 container 起不来,因此 LimitRange 不常用。init container 很多时候可能会占用很多资源,但是执行完就会回收。)
分配出去的内存则是直接扣除掉,而且通常不会主动回收。
磁盘资源需求
容器临时存储(ephemeral storage)包含日志和可写层数据,可以通过定义 Pod Spec 中的 limits.ephemeral-storage 和 requests.ephemeral-storage 来申请。
Pod 调度完成后,计算节点对临时存储的限制不是基于 Cgroup 的,而是由 kubelet 定时获取容器的日志和容器可写层的磁盘使用情况,如果超过限制,则会对 Pod 进行驱逐。
Init Container 的资源需求
1 | kubectl explain Pod.spec.initContainers |
定义中,是一个数组,会一个一个顺序执行(因此资源需求只看最多的一个),只执行一次,执行完则退出,如果没有全部执行完并且退出,下面的 Containers 不会执行。
- 当
kube-scheduler调度带有多个init容器的 Pod 时,只计算cpu.request最多的init容器,而不是计算所有的init容器总和 - 由于多个
init容器按顺序执行,并且执行完成立即退出,所以申请最多的资源init容器中的所需资源,即可满足所有init容器需求 kube-scheduler在计算该节点被占用的资源时,init容器的资源依然会被纳入计算。因此init容器在特定情况下可能会被再次执行,比如由于更换镜像而引起Sandbox重建时
把 Pod 调度到指定 Node 上
- 可以通过
nodeSelector、nodeAffinity、podAffinity以及Taints和tolerations等来将 Pod 调度到需要的 Node 上 - 也可以通过设置
nodeName参数,将Pod调度到指定node节点上。
比如,使用 nodeSelector,首先给 Node 加上标签:
kubectl label nodes <your-node-name> disktype=ssd
接着,指定该 Pod 只想运行在带有 disktype=ssd 标签的 Node 上
1 | apiVersion: apps/v1 |
noedSelector
首先给 Node 打上标签:
1 | kubectl label nodes node-01 disktype=ssd |
然后在 daemonset 中指定 nodeSelector 为 disktype=ssd
1 | spec: |
NodeAffinity
节点亲和性
1 | kubectl explain Pod.spec.affinity.nodeAffinity |
NodeAffinity 目前支持两种:requiredDuringSchedulingIgnoredDuringExecution 和 preferredDuringSchedulingIgnoredDuringExecution,分别代表必须满足条件和优选条件。
比如下面的例子代表调度必须包含标签 a 并且值为 b 或 c 的 Node 上,并且优选(打分,选择分数最高)还带有标签 app=anti-nginx 的 Node
1 | apiVersion: apps/v1 |
PodAffinity
1 | kubectl explain Pod.spec.affinity.podAffinity |
pod 亲和性
podAffinity 基于 Pod 的标签来选择 Node,仅调度到满足条件 Pod 所在的 Node 上,支持 podAffinity 和 podAntiAffinity。
如果一个 Node 所在 Zone 中包含至少一个带有 security=S1 标签,且运行中的 Pod,那么可以调度到该 Node,不调度到包含至少一个带有 security=S2 标签且运行中 Pod 的 Node 上。
1 | apiVersion: v1 |
使用多个副本的 deployment 示例:
1 | apiVersion: apps/v1 |
Taints 和 Tolerations
Taints 和 Tolerations 用于保证 Pod 不被调度到不合适的 Node 上,其中 Taint 应用于 Node 上,而 Toleration 则应用于 Pod 上。
目前支持的 Taint 类型:
NoSchedule:新的Pod不调度到该Node上,不影响正在运行的PodPerferNoSchedule:soft版的NoSchedule,尽量不调度到该Node上NoExecute:新的Pod不调度到该Node上,并且删除(evict) 已在运行的Pod。Pod可以增加一个时间(tolerationSeconds)
然而,当 Pod 的 Tolerations 匹配 Node 的所有 Taints 的时候,可以调度到该 Node 上;当 Pod 是已经运行的时候,也不会被删除(evicted)。另外对于 NoExecute,如果 Pod 增加了一个 tolerationSeconds,则会在该时间之后才删除 Pod。
1 | kubectl explain pod.spec.tolerations |
使用方式:给节点打上污点,禁止被调度。(例如使用 kubeadm 安装之后,上面会有 NoSchedule 的污点)
1 | kubectl taint nodes cadmin for-special-user=cadmin:NoSchedule |
去掉污点
1 | kubectl taint nodes cadmin for-special-user=cadmin:NoSchedule- |
例如 codedns
1 | kubectl get pod coredns-857d9ff4c9-fnvm9 -o yaml |
多租户 Kubernetes 集群 - 计算资源隔离
Kubernetes 集群一般是通用集群,可被所有用户共享,用户无需关心计算节点细节。
但往往某些自带计算资源的客户要求:
- 带着计算资源加入 Kubernetes 集群
- 要求资源隔离
实现方案:
- 将要隔离的计算节点打上
Taints - 在用户创建
Pod时,定义tolerations来指定要调度到node taints
该方案有几个漏洞,以及解决方法:
- 其他用户如果可以
get nodes或者pods,可以看到taints信息,也可以用相同的tolerations占用资源- 不让用户
get node details,利用apiserver的授权能力,控制只读权限, - 不让用户
get别人的pod details - 企业内部,也可以通过规范管理,通过统计数据看谁占用了哪些
node
- 不让用户
- 数据平面上的隔离还需要其他方案配合
来自生产系统的经验
- 用户会忘记打
tolerance,导致pod无法调度,pending:查看状态来解决 - 新员工常犯的错误,通过聊天机器人的
Q&A解决 - 其他用户会
get node detail,查到Taints,偷用资源:权限控制
运维侧:
- 通过
dashboard,能看到哪些用户的什么应用跑在哪些节点上 - 对于违规用户,批评教育为主
优先级调度
从 v1.8 开始,kube-scheduler 支持定义 Pod 的优先级,从而保证高优先级的 Pod 优先调度。开启方法为:
apiserver配置--feature-gates=PodPriority=true和 `–runtime-config=scheduling.k8s.io/v1alpha1=true``- ``kube-scheduler
配置–feature-gates=PodPriority=true`
PriorityClass
在指定 Pod 的优先级之前需要先定义一个 PriorityClass(非 namespace 资源),如:
1 | apiVersion: scheduling.k8s.io/v1 |
优先级是抢占式的,当需要调度优先级高的 Pod 时,判断资源是否满足,如果不满足,会从优先级最低的资源开始杀死,直到资源满足,再优先调度。
为 pod 设置 priority
1 | apiVersion: v1 |
多调度器
如果默认的调度器不满足要求,还可以部署自定义的调度器。
并且,在整个集群中还可以同时运行多个调度器实例,通过 podSpec.SchedulerName 来选择使用哪一个调度器(默认使用内置的调度器)
例如批次调度器,一次性调度多个任务。
来自生产的一些经验
小集群
100个
node,并发创建 8000 个Pod的最大调度消耗时大概是 2 分钟左右,发生过node删除后,scheduler cache还有信息的情况,导致Pod调度失败放大效应
当一个
node出现问题导致load较小时(由于kubelet出现异常,导致检测不及时),通常用户的Pod都会优先调度到该node上,导致用户所有创建的新Pod都失败的情况应用炸弹
存在危险的用户
Pod(比如fork bomb),在调度到某个node上以后,会因为打开文件句柄过多(fork很多的子进程,将pid占用完)导致nodedown机,Pod会被evict到其他节点,再对其他节点造成伤害,一次循环会导致整个cluster所有节点不可用。
调度器可以说是运营过程中最稳定性最好的组件之一,基本没有太大的维护 effort。
调度逻辑,源码:pkg/scheduler/schedule_one.go
Controller Manager
控制器的工作流程

Informer:监听对象,例如 pod informer,监听 pod 对象变更,作为生产者,将对象的 key 放到 queue 中
Lister:保留 apiserver 的缓存,减少 controller 对 apiserver 调度
worker:消费者,获取变更的对象
Informer 的内部机制

informer 内部也是一个生产者消费者模型。
控制器的协同工作原理

例如一个 deployment,是由多个控制器,协同工作,完成部署。
通用 Controller
获取 controller 的运行命令:
1 | kubectl get pod kube-controller-manager-master -o yaml |
获取命令参数:
1 | kubectl exec -it kube-controller-manager-master -- kube-controller-manager --help |
获取所有可用的 controller
1 | --feature-gates mapStringBool |
一些常用的控制器:
Job Controller:处理job,用于批处理作业1
2
3
4
5
6
7
8
9
10
11
12
13
14apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
parallelism: 2 # 并发个数,每次创建 2 个 Pod
completions: 5 # 执行次数,总共创建 5 个 Pod
template:
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"] # 例如计算 Pi 的两千位
restartPolicy: OnFailure执行完之后,会以
Completed状态保留住Pod,并且可以查看日志。清理时,直接删除Job即可。Pod AutoScaler:处理pod的自动缩容、扩容,当处理请求负载高的时候,自动扩容,当负载降低时,自动缩容ReplicaSet:依据Replicaset Sepc创建Pod无状态副本
Service Controller:为LoadBalancer type的service创建LB VIPServiceAccount Controller:确保serviceaccount在当前namespace存在StatefulSet Controller:处理statefulset中的pod有状态副本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31apiVersion: apps/v1
kind: StatefulSet
metadata:
name: nginx-ss
spec:
serviceName: nginx-ss
replicas: 1
selector:
matchLabels:
app: nginx-ss
template:
metadata:
labels:
app: nginx-ss
spec:
containers:
- name: nginx-ss
image: nginx
apiVersion: v1
kind: Service # StatefulSet 必须与 Service 一起出现
metadata:
name: nginx-ss
labels:
app: nginx-ss
spec:
ports:
- port: 80
clusterIP: None # StatefulSet 的 clusterIP 是 None,通过不同的域名访问对应一个 StatefulSet
selector:
app: nginx-ssVolume Controller:依据PV spec创建volumeResource quota Controller:在用户使用资源之后,更新状态Namespace Controller:保证namespace删除时,该namespace下的所有资源都先被删除pkg/controller/namespace/namespace_controller.goReplication Controller:创建RC后,负责创建Pod(基本不用)Node Controller:维护node状态,处理evict请求等处理节点上的
Taints和对应Pod的管理Daemon Controller:依据daemonset创建pod一般给集群管理员使用,个数与节点数对应,而且
tolerations非常多,例如一个daemonset的 Pod1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23tolerations:
- operator: Exists
- effect: NoExecute
key: node.kubernetes.io/not-ready
operator: Exists
- effect: NoExecute
key: node.kubernetes.io/unreachable
operator: Exists
- effect: NoSchedule
key: node.kubernetes.io/disk-pressure
operator: Exists
- effect: NoSchedule
key: node.kubernetes.io/memory-pressure
operator: Exists
- effect: NoSchedule
key: node.kubernetes.io/pid-pressure
operator: Exists
- effect: NoSchedule
key: node.kubernetes.io/unschedulable
operator: Exists
- effect: NoSchedule
key: node.kubernetes.io/network-unavailable
operator: ExistsDeployment Controller:依据deployment spec创建replicasetEndpoint Controller:依据service spec创建endpoint,依据podip更新endpointGarbage Collector:处理级联删除,比如删除deployment的同时删除replicaset以及pod例如只删除
deployment,但是不删除rs和pod1
kubectl delete deployments.apps nginx --cascade=orphan
CronJob Controller:处理cronjob
Cloud Controller Manager
Cloud Controller Manager 自 Kubernetes 1.6 开始,从 kube-controller-manager 中分离出来,主要因为 Cloud Controller Manager 往往需要跟企业 cloud 做深度集成,release cycle 跟 Kubernetes 相对独立。
与 Kubernetes 核心管理组件一起升级是一件费事费力的事。
通常 cloud controller manager 需要:
- 认证授权:企业
cloud往往需要认证信息,Kubernetes要与Cloud API通信,需要获取cloud系统里的ServiceAccount; Cloud Controller Manager本身作为一个用户态的component,需要在Kubernetes中有正确的RBAC设置,获得资源操作权限- 高可用:需要通过
leader election来确保cloud controller manager高可用
配置
cloud Controller manager 是从老版本的 APIServer 分离出来的
Kube-APIServer和kube-controller-manager中一定不能指定cloud-provider,否则会加载内置的 `cloud controller manager``- ``Kubelet
要配置–cloud-provider=external`
Cloud Controller Manager 主要支持:
Node Controller:访问cloud API,来更新node状态;在cloud删除该节点以后,从Kubernetes删除nodeService Controller:负责配置为loadbalancer类型的服务配置LB VIPRoute Controller:在cloud环境配置路由;- 可以自定义任何需要的
Cloud Controller
一些厂商会提供对应的 controller
需要定制的 Cloud controller
Ingress ControllerService Controller- 自主研发的
Controller,比如之前提到的:RBAC ControllerAccount Controller
来自生产的经验
保护好 controller manager 的 kubeconfig,避免出现权限管理漏洞,引发其他问题:
- 此
kubeconfig拥有所有资源的所有操作权限,防止普通用户通过kubectl exec kube-controller-manager cat获取该文件 - 用户可能做任何你想象不到的操作,然后来找你
support
Pod evict 后 IP 发生变化,但 endpoint 中的 address 更新失败:
- 分析
stacktrace发现endpoint在更新LoadBalancer时调用gophercloud连接hang住,导致endpoint worker线程全部卡死
确保 scheduler 和 controller 的高可用
Leader Election:高可用方案依据 Leader、Follower,多个 controller 部署上去,但是确保只有一个 controller 在工作。
- Kubernetes 提供基于
configmap和endpoint的leader election类库
Kubernetes 采用 leader election 模式启动 component 后,会创建对应 endpoint,并把当前的 leader 信息 annotate 到 endpoint 上

holderIdentity:当前获得锁的对象
leaseDurationSeconds:持有锁的时间
acquireTime:获取锁的时间
renewTime:锁更新时间
leaderTransition:任期
Follower 通过 leaseDurationSeconds 和 renewTime 判断锁是否有效,无效的话则开始抢锁。
现在 Kubernetes 将这些都放在 lease 里面
1 | # kubectl get leases.coordination.k8s.io kube-controller-manager -n kube-system -o yaml |
Leader Election
竞争 Leader 流程:

kubelet
kubelet 架构

ProbeManager:探活检测OOMWatcher:检测内存GPUManager:管理 GPUcAdvisor:通过cGroup收集容器使用资源用量进行上报syncLoop:同步 Pod 状态PodWorker:获取 Pod 状态改动,更新 Pod 状态DiskSpaceManager:节点磁盘空间管理StatusManager:节点状态管理EvictionManager:资源不足时 Pod 驱逐管理Volume Manager:Volume管理Image GC:当磁盘空间不足,将镜像回收Container GC:磁盘空间不足,将已经退出的容器回收Container Runtime Interface:CRI
kubelet 管理 Pod 的核心流程

kubelet 也是一个控制器模式
- 通过三个源检测 Pod 状态更新,分别是
APIServer、file、httpAPIServer:配置APIServer地址监听,获取Pod变化file:静态文件,一般在/etc/kubernetes/manifests/下http:自建http服务器,返回 Pod 信息
syncLoop:生产者生产数据队列worker:消费者computePodActions:对比当前 Pod 状态和变更的状态,对 Pod 进行操作,通过CRI进行create或者kill
PLEG:通过CRI罗列 Pod,收集当前节点所有 Pod 信息,通过lifecycle event上报到master节点
kubelet
每个节点上都运行一个 kubelet 服务进程,默认监听 10250 端口
- 接收并执行
master发来的指令 - 管理
Pod及Pod中的容器 - 每个
kubelet进程会在APIServer上注册节点自身信息,定期向master节点汇报节点的资源使用情况,并通过cAdvisor监控节点和容器的资源
节点管理
节点管理主要是节点自注册和节点状态更新:
kubelet可以通过设置启动参数--register-node来确定是否向API Server注册自己- 如果
kubelet没有选择自注册模式,则需要用户自己配置Node资源信息,同时需要告知kubelet集群上的API Server的位置 kubelet在启动时通过API Server注册节点信息,并定时向API Server发送节点新信息,API Server在接收到新消息后,将信息写入etcd
Pod 管理
获取 Pod 清单:
- 文件:启动参数
--config指定的配置目录下的文件(默认/etc/kubernetes/manifests/)。该文件每 20 秒重新检查一次(可配置) HTTP endpoint(URL):启动参数--manifest-url设置。每 20 秒检查一次这个端点(可配置)API Server:通过API Server监听etcd目录,同步Pod清单HTTP server:kubelet侦听HTTP请求,并响应简单的API以提交新的Pod清单
Pod 启动流程

用户:
deployment Controller、Replication Controller等通过调用
APIServer创建PodAPIServer将信息写入etcd做持久化Scheduler通过监听APIServer的变化,进行调度,将Pod绑定到Node上(过滤、打分、选择最佳node),将调度结果写入APIServerAPIServer将调度结果写入etcd做持久化Kubelet通过监听APIServer上Pod的变化,与本节点Pod状态进行对比,创建Podkubelet调用CRI接口里面的RunPodSandbox的APISandbox的意义:1
2
3# docker ps | grep coredns-778779dd5d-4lg2p
7045f9ee77f5 70f311871ae1 "/coredns -conf /etc…" 25 hours ago Up 25 hours k8s_coredns_coredns-778779dd5d-4lg2p_kube-system_992e5dff-1236-4ab1-94ee-07ac7e488ee7_5
6987d08bbdf2 k8s.gcr.io/pause:3.1 "/pause" 25 hours ago Up 25 hours k8s_POD_coredns-778779dd5d-4lg2p_kube-system_992e5dff-1236-4ab1-94ee-07ac7e488ee7_5例如一个
coredns的Pod中启动两个container,其中一个是pause,保持sleep,极度稳定,不消耗 CPU 和内存。这种情况下,就可以将各种namespace挂载上去,例如网络,那么网络配置就极度稳定。又例如一些容器需要提前将网络准备就绪,此时使用
pause就可以在启动容器之前将网络准备就绪。pause与运行进程隔离开,可以保障当业务进程异常,pod依然可以ping通,当然,业务端口是异常的。通过
SetUpPod调用网络插件获得分配的 IPkubelet拉取进行,创建Container将
pod信息回写到APIServer
Kubelet 启动 Pod 的详细流程

流程的一些补充:
- 开始启动 Pod 的时候,还可以使用准入插件
- 检查网络插件状态
- 更新
cgroup - 创建数据目录
- 如果有外部存储,等待
Volume挂载就绪以及挂载 syncPod- 计算
sandbox和container变更 - 如果发生变更,则
kill pod - 清空
init Container - 创建
sandbox- 生成
sandboxconfig - 创建
pod日志目录 - 调用 CRI 运行
Sandbox - 确保镜像存在,拉取镜像
- 创建网络
namespace - 调用
cni接口,安装pod网络- 在
cni中通过网络插件,创建网络
- 在
- 创建
sandbox容器根目录
- 生成
- 计算
可以看到,CRI、CNI、CSI 的调用顺序为:先调用 CSI 将 volume attach;再调用 CRI 启动 sandbox,最后调用 CNI 创建网络。
CRI
容器运行时 (Container Runtime),运行于 Kubernetes(k8s)集群的每个节点中,负责容器的整个生命周期。其中 Docker 是目前应用最广的。随着容器云的发展,越来越多的容器运行时涌现。为了解决这些容器运行时和 Kubernetes 的集成问题,在 Kubernetes 1.5 版本中,社区推出了 CRI(Container Runtime Interface,容器运行时接口)以支持更多的容器运行时。

CRI 介绍
CRI 是 Kubernetes 定义的一组 gRPC 服务(HTTP/2 协议 + protocbuf 数据结构)。kubelet 作为客户端,基于 gRPC 框架,通过 Socket 和容器运行时通信。它包括两类服务:镜像服务(Image Service)和运行时服务(Runtime Service)。镜像服务提供下载、检查和删除镜像的远程程序调用。运行时服务包含用于管理容器生命周期,以及与容器交互的调用(exec/attach/port-forward)的远程程序调用。

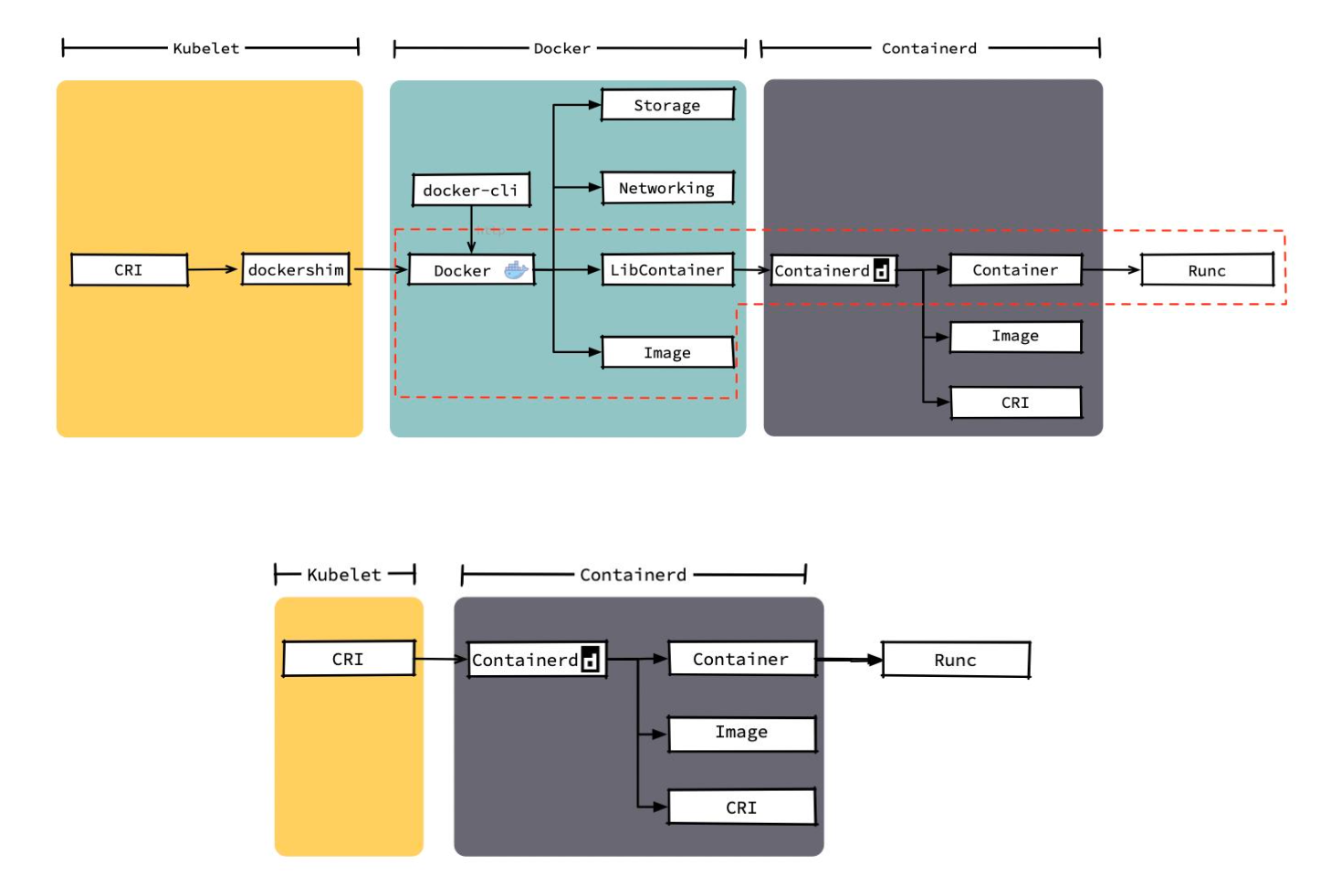
运行时的层次
Dockershim,containerd 和 CRI-O 都是遵循 CRI 的容器运行时,我们称他们为 高层级运行时(High-level Runtime) (可以理解为高层级运行时对外提供服务)
OCI(Open Container Initiative,开放容器计划)定义了创建容器的格式和运行时的开源行业标准,包括镜像规范(Image Specification)和运行时规范(Runtime Specification)。
镜像规范定义了 OCI 镜像的标准。高层级运行时将会下载一个 OCI 镜像,并把他解压成 OCI 运行时文件系统包(filesystem bundle)
运行时规范则描述了如何从 OCI 运行时文件系统包运行容器程序,并且定义它的配置、运行环境和生命周期。如何为新容器设置命名空间(namespace)和控制组(cgroups),以及挂载根文件系统等等操作,都是在这里定义的。它的一个参考实现是 runC。我们称其为 低层级运行时(Low-level Runtime)。除 runC 以外,也有很多其他的运行时遵循 OCI 标准,例如 kata-runtime。
CRI 功能
容器运行时是真正启动、删除和管理容器的组件。容器运行时可以分为高层和底层的运行时。
高层运行时主要包括 Docker,containerd 和 CRI-O;底层的运行时,包含了 runC,kata,以及 gVisor。
底层运行时 kata 和 gVisor 都还处于小规模落地或者实验阶段,其生态成熟度和使用案例都比较欠缺,所以除非有特殊的需求,否则 runC 几乎是必然的选择。因此在对容器运行时的选择上,主要是聚焦于上层运行时的选择。
Docker 内部关于容器运行时功能的核心组件是 containerd,后来 containerd 也可直接和 kubelet 通过 CRI 对接,独立在 Kubernetes 中使用。相对于 Docker 而言,containerd 减少了 Docker 所需的处理模块 Dockerd 和 Docker-shim,并且对 Docker 支持的存储驱动进行了优化,因此在容器的创建、启动、停止和删除,以及对镜像的拉取上,都具有性能上的优势。架构简化同时也带来了维护的便利。
当然 Docker 也具有很多 containerd 不具有的功能,例如支持 zfs 存储驱动,支持对日志的大小和文件限制,在以 overlayfs2 做存储驱动的情况下,可以通过 xfs_quota 来对容器的可写层进行大小限制等。
尽管如此,containerd 目前也基本上能够满足容器的众多管理需求,所以将它作为运行时的也越来越多。
kubelet 和运行时的关系:

CRI 提供 RuntimeService 和 ImageService

开源运行时的比较
Docker 的多层封装和调用,导致其在可维护性上略逊一筹,增加了线上问题的定位难度;几乎除了重启 Docker,我们就毫无他法了。
containerd 和 CRI-O 的方案比起 Docker 简洁很多。

相比而言,使用 dockershim ,其实是 Docker 将 containerd 进一步封装,kubelet 最终调用 OCI Runtime 过程更加繁琐。
Docker 和 containerd 的差异细节
多种运行时性能比较
containerd 在各个方面都表现良好,除了启动容器这项。
从总用时来看,containerd 的用时还是要比 CRI-O 要短的。

运行时优劣对比
功能性来将,containerd 和 CRI-O 都符合 CRI 和 OCI 的标准;
在稳定性上,containerd 略胜一筹
从性能上讲,containerd 胜出。
| containerd | CRI-O | 备注 | |
|---|---|---|---|
| 性能 | 更优 | 优 | |
| 功能 | 优 | 优 | CRI 与 OCI 兼容 |
| 稳定性 | 稳定 | 未知 |
相比三种方案,containerd 的方案更优。
CRI 操作
当使用 docker 作为 CRI 时,可以通过 docker ps 查看到容器运行状态。也可以使用 ctr -n k8s.io c ls 命令查看,还可以使用 crictl pods 命令查看。
1 | docker ps |
切换 CRI
先停掉
kubelet、docker和containerd1
2
3systemctl stop kubelet
systemctl stop docker.socket
systemctl stop containerd修改
containerd配置文件1
2
3
4
5
6
7mkdir -p /etc/containerd/
// 将 配置 dump 出来
containerd config default | tee /etc/containerd/config.toml
// 修改配置,将 pause 镜像的地址改为 aliyun
// 修改配置,将 systemdCgroup 改为 ture
sed -i s#k8s.gcr.io/pause:3.5#registry.aliyuncs.com/google_containers/pause:3.5#g /etc/containerd/config.toml
sed -i s#'SystemdCgroup = false'#'SystemdCgroup = true'#g /etc/containerd/config.toml查看
kubelet服务启动配置1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20systemctl status kubelet
● kubelet.service - kubelet: The Kubernetes Node Agent
Loaded: loaded (/lib/systemd/system/kubelet.service; enabled; vendor preset: enabled)
Drop-In: /usr/lib/systemd/system/kubelet.service.d
└─10-kubeadm.conf
Active: inactive (dead) since Tue 2024-01-23 03:03:31 UTC; 6min ago
Docs: https://kubernetes.io/docs/
Process: 1241 ExecStart=/usr/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_CONFIG_ARGS $KUBELET_KUBEADM_ARGS $KUBELET_EXTRA_ARGS (code=exited, status=0/SUCCESS)
Main PID: 1241 (code=exited, status=0/SUCCESS)
Jan 23 02:18:05 master kubelet[1241]: E0123 02:18:05.661831 1241 kuberuntime_manager.go:1172] "CreatePodSandbox for pod failed" err="rpc error: code = Unknown desc = failed to set>
Jan 23 02:18:05 master kubelet[1241]: E0123 02:18:05.661990 1241 pod_workers.go:1298] "Error syncing pod, skipping" err="failed to \"CreatePodSandbox\" for \"coredns-857d9ff4c9-fn>
Jan 23 02:18:01 master kubelet[1241]: I0123 02:18:01.986626 1241 kuberuntime_container_linux.go:167] "No swap cgroup controller present" swapBehavior="" pod="kube-system/coredns-8>
Jan 23 02:18:06 master kubelet[1241]: I0123 02:18:06.567990 1241 kuberuntime_container_linux.go:167] "No swap cgroup controller present" swapBehavior="" pod="kube-system/coredns-8>
Jan 23 02:18:17 master kubelet[1241]: I0123 02:18:17.642092 1241 kuberuntime_container_linux.go:167] "No swap cgroup controller present" swapBehavior="" pod="default/nginx-56fcf95>
Jan 23 02:18:24 master kubelet[1241]: I0123 02:18:24.368059 1241 kuberuntime_container_linux.go:167] "No swap cgroup controller present" swapBehavior="" pod="default/nginx-56fcf95>
Jan 23 03:03:31 master kubelet[1241]: I0123 03:03:31.905086 1241 dynamic_cafile_content.go:171] "Shutting down controller" name="client-ca-bundle::/etc/kubernetes/pki/ca.crt"
Jan 23 03:03:31 master systemd[1]: Stopping kubelet: The Kubernetes Node Agent...
Jan 23 03:03:31 master systemd[1]: kubelet.service: Succeeded.
Jan 23 03:03:31 master systemd[1]: Stopped kubelet: The Kubernetes Node Agent.配置文件是
/usr/lib/systemd/system/kubelet.service.d/10-kubeadm.conf(有些环境可能是/etc/systemd/system/kubelet.service.d/10-kubeadm.conf)修改启动参数,新增一个配置文件
1
2vi /usr/lib/systemd/system/kubelet.service.d/10-kubeadm.conf
Environment="KUBELET_EXTRA_ARGS=--container-runtime=remote --container-runtime-endpoint=unix:///run/containerd/containerd.sock --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.5"重启服务
1
2
3systemctl daemon-reload
systemctl restart containerd
systemctl restart kubelet修改
crictl命令配置1
2
3cat <<EOF | sudo tee /etc/crictl.yaml
runtime-endpoint: unix:///run/containerd/containerd.sock
EOF
CNI
Kubernetes 网络模型设计的基础原则是:
- 所有的
Pod能够不通过NAT就能相互访问 - 所有的节点能够不通过
NAT就能相互访问 - 容器内看见的
IP地址和外部组件看到的容器IP是一样的
Kubernetes 的集群里,IP 地址是以 Pod 为单位进行分配的,每个 Pod 都拥有一个独立的 IP 地址。
一个 Pod 内部的所有容器共享一个网络栈,即主机上的一个网络命名空间,包括它们的 IP 地址、网络设备、配置等都是共享的。也就是说,Pod 里面的所有容器能通过 localhost:port 来连接对方。在 Kubernetes 中,提供了一个轻量的通用容器网络接口 CNI(Container Network Interface),专门用于设置和删除容器的网络连通性。容器运行时通过 CNI 调用网络插件来完成容器的网络设置。
CNI 插件分类和常见插件
IPAM:IP 分配器,用于 IP 地址分配- 主插件:网卡设置
bridge:创建一个网桥,并把主机端口和容器端口插入网桥ipvlan:为容器添加ipvlan网口loopback:设置loopback网口
Meta:附加功能portmap:设置主机端口和容器端口映射bandwidth:利用Linux Traffic Control限流firewall:通过iptables或firewall为容器设置防火墙规则
https://github.com/containernetworking/plugins
CNI 插件运行机制
容器运行时在启动时会从 CNI 的配置目录(默认目录 /etc/cni/net.d/ )中读取 JSON 格式的配置文件,文件后缀为 .conf、.conflist、.json。如果配置目录中包含多个文件,一般情况下,会以名字排序选用第一个配置文件作为默认的网络配置,并加载获取其中指定的 CNI 插件名称和配置参数。
默认可执行文件位置:/opt/cni/bin/
1 | # ls /opt/cni/bin/ |

CNI 的运行机制
关于容器网络管理,容器运行时一般需要配置两个参数 --cni-bin-dir 和 --cni-conf-dir。有一种特殊情况,kubelet 内置的 Docker 作为容器运行时,是由 kubelet 来查找 CNI 插件的,运行插件来为容器设置网络,这两个参数应该配置在 kubelet 处:
cni-bin-dir:网络插件的可执行文件所在目录。默认是/opt/cni/bincni-conf-dir:网络插件的配置文件所在目录。默认是/etc/cni/net.d
CNI 插件设计考量
- 容器运行时必须在调用任何插件之前为容器创建一个新的网络命名空间
- 容器运行时必须决定这个容器属于哪些网络,针对每个网络,哪些插件必须要执行
- 容器运行时必须加载配置文件,并确定设置网络时哪些插件必须被执行
- 网络配置采用
JSON格式,可以很容易地存储在文件中 - 容器运行时必须按顺序执行配置文件里相应的插件(配置文件中多个
plugins时,链式调用) - 在完成容器生命周期后,容器运行时必须按照与执行添加容器相反的顺序执行插件,以便将容器与网络断开连接
- 容器运行时被同一容器调用时不能并行操作,但被不同的容器调用时,允许并行操作
- 容器运行时针对一个容器必须按顺序执行
ADD和DEL操作,ADD后面总是跟着相应的DEL。DEL可能跟着额外的DEL,插件应该允许处理多个DEL - 容器必须由
ContainerID来唯一标识,需要存储状态的插件需要使用网络名称、容器ID和网络接口组成的主key用于索引 - 容器运行时针对同一个网络、同一个容器、同一个网络接口,不能连续调用两次
ADD命令
打通主机层网络
CNI 插件外,Kubernetes 还需要标准的 CNI 插件 lo,最低版本为 0.2.0 版本。
网络插件除支持设置和清理 Pod 网络接口外,该插件还需要支持 iptables。
如果 Kube-proxy 工作在 iptables 模式,网络插件需要确保容器流量能使用 iptables 转发。例如,网络插件将容器连接到 Linux 网桥,必须将 net/bridge/bridge-nf-call-iptables 参数 sysctl 设置为 1,网桥上数据包将遍历 iptables 规则。
如果插件不使用 Linux 桥接器(而是类似 Open vSwitch 或其他某种机制的插件),则应确保容器流量被正确设置了路由。
CNI Plugin
ContainerNetworking 组维护了一些 CNI 插件,包括网络接口创建的 bridge、ipvlan、loopback、macvlan、ptp、host-device 等,IP 地址分配的 DHCP、host-local 和 static,其他的 Flannel、tunning、portmap、firewalld 等。
社区还有些第三方网络策略方面的插件,例如 Calic、Cilium 和 Weave 等。可用选项的多样性意味着大多数用户将能够找到适合当前需求和部署环境的的 CNI 插件,并在情况变化时迅捷转换解决方案。(Calic 和 Cilium 这两个插件比较推荐,是完备的解决方案)
Flannel
Flannel 是由 CoreOS 开发的项目,是 CNI 插件早期的入门产品,简单易用。
Flannel 使用 Kubernetes 集群的现有 etcd 集群来存储其状态信息,从而不必提供专用的数据存储,只需要在每个节点上运行 flanneld 来守护进程。
每个节点都被分配一个子网,为该节点上的 Pod 分配 IP 地址。
同一主机内的 Pod 可以使用网桥进行通信,而不同主机上的 Pod 将通过 flanneld 将其流量封装在 UDP 数据包中,以路由到适当的目的地。
封装方式默认和推荐的方法是使用 VxLAN,因为它具有良好的性能,并且比其他选项要少些人为干预。虽然使用 VxLAN 之类的技术封装的解决方案效果很好,但缺点就是该过程使流量跟踪变得困难。

Calico
Calico 以其性能、灵活性和网络策略而闻名,不仅涉及在主机和 Pod 之间提供网络连接,而且还涉及网络安全性和策略管理。
对于同网段通信,基于第 3 层,Calico 使用 BGP 路由协议在主机之间路由数据包,使用 BGP 路由协议也意味着数据包在主机之间移动时不需要包装在额外的封装层中。
对于跨网段通信,基于 IPinIP (Calico 支持多种,也支持 VxLan)使用虚拟网卡设备 tunl0,用一个 IP 数据包封装另一个 IP 数据包,外层 IP 数据包头的源地址为隧道入口设备的 IP 地址,目标地址为隧道出口设备的 IP 地址。
网络策略是 Calico 最受欢迎的功能之一,使用 ACLs 协议和 kube-proxy 来创建 iptables 过滤规则,从而实现隔离容器网络的目的。
此外,Calico 还可以与服务网络 Istio 集成,在服务网格层和基础结构层上解释和实施集群中工作负载的策略。这意味着您可以配置功能强大的规则,以描述 Pod 应该如何发送和接受流量,提高安全性及加强对网络环境的控制。
Calico 属于完全分布式的横向扩展接口,允许开发人员和管理员快速和平稳地扩展部署规模。对于性能和功能(如网络策略)要求高的环境,Calico 是一个不错选择。
Calico 组件

Calico 初始化
配置和 CNI 二进制文件由 initContainer 推送
https://docs.projectcalico.org/manifests/calico.yaml
1 | # This container installs the CNI binaries |
Calico 配置一览
1 | { |
Calico VXLan

例如 Pod 跨主机通信时,本机 Pod 通过 vxlan-calico 将包重新封装,数据传输到另外一个 Node 之后,解封装。
IPPool
IPPool 用来定义一个集群的预定义 IP 段
1 | # kubectl get ippools.crd.projectcalico.org -o yaml |
IPAMBlock
IPAMBlock 用来定义每个主机预分配的 IP 段
1 | # kubectl get ipamblocks.crd.projectcalico.org |
新建两个 Pod 之后
1 | - handle_id: k8s-pod-network.1ff620c63d340470341e83d594a6c8d4e3a86c40e4cf3cc5cec695dcf32fb036 |
IPAMHandle
IPAMHandle 用来记录 IP 分配的具体细节
1 | # kubectl get ipamhandles.crd.projectcalico.org |
查看 Pod 之间的网络通信方式
1 | # kubectl get pod calico-node-5dd86 -n calico-system -o yaml |
单一节点上的路由
1 | kubectl get pod -o wide |
查看主机上对应端口信息
1 | ip a |
可以看到,发出的包会被主机获取
主机通过路由表信息,获取对端网口,将网络请求转发过去
1 | # ip r |
通过 BGP 交换路由信息
1 | ip r |
创建 Pod 并查看 IP 配置情况
使用其他插件的查看过程差不多,例如 flannel
容器 namespace
1 | nsenter -t 3863 -n ip a |
主机 namespace
1 | ip link |
CNI plugin 的对比
| 解决方案 | 是否支持网络策略 | 是否支持 ipv6 | 基于网络层级 | 部署方式 | 命令行 |
|---|---|---|---|---|---|
| Calico | 是 | 是 | L3(IPinIP, BGP) | DaemonSet | calicoctl |
| Cilium | 是 | 是 | L3/L4 + L7(filtering) | DaemonSet | cilium |
| Contiv | 否 | 是 | L2(VxLan) / L3(BGP) | DaemonSet | 无 |
| Flannel | 否 | 否 | L2(VxLan) | DaemonSet | 无 |
| Weave net | 是 | 是 | L2(VxLan) | DaemonSet | 无 |
CSI
容器运行时存储
- 除外挂存储外,容器启动后,运行时所需文件系统性能直接影响容器性能;
- 早期的
Docker采用Device Mapper作为容器运行时存储驱动,因为OverlayFS尚未合并进Kernel; - 目前
Docker和containerd都默认以OverlayFS作为运行时存储驱动(镜像层,一般不会往里面写数据,仅作为将运行时拉起来的存储); OverlayFS目前已经有非常好的性能,与DeviceMapper相比优20%,于操作主机文件性能几乎一致;

存储卷插件管理
Kubernetes 支持以插件的形式来实现对不同存储的支持和扩展,这些扩展基于如下三种方式:
in-tree插件Kubernetes 社区已不再接受新的
in-tree存储插件,新的存储必须通过out-of-tree插件进行支持out-of-treeFlexVolume插件(与 CNI 一样的逻辑,提供二进制可执行文件,在容器内执行)FlexVolume是指 Kubernetes 通过调用计算节点的本地可执行文件与存储插件进行交互。FlexVolume插件需要宿主机用root权限来安装插件驱动FlexVolume存储驱动需要宿主机安装attach、mount等工具,也需要具有root访问权限out-of-treeCSI插件(相比而言更加适用)
out-of-tree CSI 插件
- CSI 通过 RPC 与存储驱动进行交互
- 在设计 CSI 的时候,Kubernetes 对 CSI 存储驱动的打包和部署要求很少,主要定义了 Kubernetes 的两个相关模块:
kube-controller-manager:kube-controller-manager模块用于感知CSI驱动存在- Kubernetes 的主控模块通过
Unix domain socket(而不是CSI驱动)或者其他方式进行直接地交互 - Kubernetes 的主控模块只与 Kubernetes 相关的
API进行交互 - 因此
CSI驱动若有依赖于 KubernetesAPI的操作,例如卷的创建、卷的attach、卷的快照等,需要在CSI驱动里面通过 Kubernetes 的API,来触发相关的CSI操作
kubeletkubelet模块用于与CSI驱动进行交互kubelet通过Unix domain socket向CSI驱动发起CSI调用(如NodeStageVolume、NodePublishVolume等),再发起mount卷和umount卷kubelet通过插件注册机制发现CSI驱动及用于和CSI驱动交互的Unix Domain Soclet- 所有部署在 Kubernetes 集群中的
CSI驱动都要通过kubelet的插件注册机制来注册自己
CSI 驱动
CSI 的驱动一般包含 external-attacher、external-provision、external-resizer、external-snapshotter、node-driver-register、CSI driver 等模块,可以根据实际的存储类型和需求进行不同方式的部署。驱动器以 DaemonSet 的形式部署在所有节点。

临时存储
常见的临时存储主要就是 emptyDir 卷;
1 | apiVersion: apps/v1 |
emptyDir 是一种经常被用户使用的卷类型,顾名思义,卷 最初是空的。
当 Pod 从节点上删除时,emptyDir 卷中的数据也会被永久删除。但当 Pod 的容器因为某些原因退出再重启时,emptyDir 卷内的数据并不会丢失。
默认情况下,emptyDir 卷存储支持在该节点所使用的存储介质上,可以是本地磁盘或网络存储。
emptyDir 也可以通过将 emptyDir.medium 字段设置为 Memory 来通知 Kubernetes 为容器安装 tmpfs,此时数据被存储在内存中,速度相对于本地存储和网络存储快很多。
1 | ~ kubectl explain pod.spec.volumes.emptyDir |
但是在节点重启的时候,内存数据会被清除;而如果存在磁盘上,则重启后数据依然存在。另外,使用 tmpfs 的内存也会计入容器的使用内存总量中,受系统的 Cgroup 限制。
1 | // 查看所有的 container |
emptyDir 设计的初衷主要是给应用充当缓存空间,或者存储中间数据,用于快速恢复。
然而,这并不是说满足以上需求的用户都被推荐使用 emptyDir,我们要根据用户业务的实际特点来判断是否使用 emptyDir。因为 emptyDir 的空间位于系统根盘,被所有容器共享,所以在磁盘的使用率较高时会触发 Pod 的 eviction 操作,从而影响业务的稳定。
半持久化存储
常见的半持久化存储主要是 hostPath 卷。hostPath 卷能将主机节点文件系统上的文件或目录挂载到指定 Pod 中。对普通用户而言一般不需要这样的卷,但是对很多需要获取节点系统信息的 Pod 而言,却是非常必要的。
使用 hostPath 一般有两种方式:
- 直接定义一个路径挂载到容器内
- 使用
PV和PVC
例如使用 PV 和 PVC 的方式
1 | # 声明 PV |
1 | # 基于 PV 声明 PVC |
1 | apiVersion: v1 |
例如,hostPath 的用法举例如下:
- 某个 Pod 需要获取节点上所有
Pod的log,可以通过hostPath访问所有 Pod 的stdout输出存储目录,例如/var/log/pods路径 - 某个
Pod需要统计系统相关的信息,可以通过hostPath访问系统的/proc目录
使用 hostPath 的时候,除设置必需的 path 属性外,用户还可以有选择性地为 hostPath 卷指定类型,支持类型包含目录、字符设备、块设备等。
hostPath 卷需要注意
使用同一个目录的 Pod 可能会由于调度到不同的节点,导致目录中的内容有所不同。
Kubernetes 在调度时无法顾及由 hostPath 使用的资源。
Pod 被删除后,如果没有特别处理,那么 hostPath 上写的数据会遗留到节点上,占用磁盘空间。
持久化存储
支持持久化的存储是所有分布式系统所必备的特性。针对持久化存储,Kubernetes 引入了 StorageClass、Volume、PVC(Persistent Volume Claim)、PV(Persistent Volume) 的概念,将存储独立于 Pod 的生命周期来进行管理。
Kubernetes 目前支持的持久化存储包含各种主流的块存储和文件存储,譬如 awsElasticBlockStore、azureDisk、cinder、NFS、cephfs、iscsi 等,在大类上可以将其分为网络存储和本地存储两种类型。
StorageClass
StorageClass 用于指示存储的类型,不同的存储类型可以通过不同的 StorageClass 来为用户提供服务。StorageClass 主要包含存储插件 provisioner、卷的创建和 mount 参数等字段。
例如 ceph
https://github.com/rook/rook/blob/master/deploy/examples/csi/cephfs/storageclass.yaml
1 | apiVersion: storage.k8s.io/v1 |
PVC
由用户创建,代表用户对存储需求的声明,主要包含需要的存储大小、存储卷的访问模式、StorageClass 等类型,其中存储卷的访问模式必须与存储的类型一致。
accessModes 字段
| 属性 | 全称 | 描述 |
|---|---|---|
| RWO | ReadWriteOnce | 该卷职能在一个节点上被 mount,属性为可读可写 |
| ROX | ReadOnlyMany | 该卷可以在不同的节点上被 mount,属性为只读 |
| RWX | ReadWriteMany | 该卷可以在不同的节点上被 mount,属性为可读可写 |
PV
由集群管理员提前创建,或者根据 PVC 的申请需求动态地创建,它代表系统后端的真实的存储空间,可以称之为卷空间。
存储对象关系
用户通过创建 PVC 来申请次存储。控制器通过 PVC 的 StorageClass 和请求的大小声明来存储后端创建卷,进而创建 PV,Pod 通过指定 PVC 来引用存储。用户层面,可以直接看到卷,而无法看到 PVC 和 PV。

生产实践经验分享
不同介质类型的磁盘,需要设置不同的 StorageClass,以便让用户做区分。StorageClass 需要设置磁盘介质的类型,以便用户了解该类存储的属性。
在本地存储的 PV 静态部署模式下,每个物理磁盘都尽量只创建一个 PV,而不是划分为多个分区来提供多个本地存储 PV,避免在使用时分区之间的 I/O 干扰。
本地存储需要配合磁盘检测来使用。当集群部署规模化后,每个集群的本地存储 PV 可能会超过几万个,如磁盘损坏将是频发时间。此时。需要在检测到磁盘损坏、丢盘的问题后,对节点的磁盘和相应的本地存储 PV 进行特殊的处理,例如出发告警、自动 cordon 节点、自动通知用户等。
对于提供本地存储节点的磁盘管理,需要做到灵活管理和自动化。节点磁盘的信息可以归一、集中化管理。在 local-volume-provisioner 中增加部署逻辑,当容器运行起来时,拉取该节点需要提供本地存储的磁盘信息,例如磁盘的设备路径,以 Filesystem 或 Block 的模式提供本地存储,或者是否需要加入某个 LVM 的虚拟组(VG)等。
local-volume-provisioner 根据获取的磁盘信息对磁盘进行格式化,或者加入到某个 VG,从而形成对本地存储支持的自动化闭环。
独占的 Local-Volume(本地存储)

- 创建 PV:通过
local-volume-provisionerDaemonSet创建本地存储的 PV - 创建 PVC:用户创建 PVC,由于它处于
pending状态,所以kube-controller-manager并不会对该 PVC 做任何操作 - 创建 Pod:用户创建 Pod
- Pod 挑选节点:
kube-scheduler开始调度 Pod,通过 PVC 的resource.request.storage和volumeMode选择满足条件的 PV,并且为 Pod 选择一个合适的节点 - 更新 PV:
kube-schedule将 PV 的pv.Spec.claimRef设置为对应的 PVC,并且设置annotation pv.kubernetes.io/bound-by-controller的值为yes - PVC 和 PV 绑定:
pv_controller同步 PVC 和 PV 的状态,并将 PVC 和 PV 进行绑定 - 监听 PVC 对象:
kube-schedule等待 PVC 的状态变成Bound状态 - Pod 调度到节点:如果 PVC 的状态变为
Bound则说明调度成功,而如果 PVC 一直处于pending状态,超时后会再次进行调度 Mount卷启动容器:kubelet监听到有 Pod 已经调度到节点上,对本地存储进行mount操作,并启动容器
Dynamic Local Volume(例如lvm或者远端)
CSI 驱动需要汇报节点上相关存储的资源信息,以便用于调度。
但是机器的厂家不同,汇报方式也不同。
例如,有的厂家的机器节点上具有 NVMe、SSD、HDD 等多种存储介质,希望将这些存储介质分别进行汇报。
这种嗯需求有别于其他存储类型的 CSI 驱动对接口的需求,因此如何汇报节点的存储信息,以及如何让节点的存储信息应用于调度,目前并没有形成统一的意见。
集群管理员可以基于节点存储的实际情况对开源 CSI 驱动和调度进行一些代码修改,再进行部署和使用。
Local Dynamic 的挂载流程
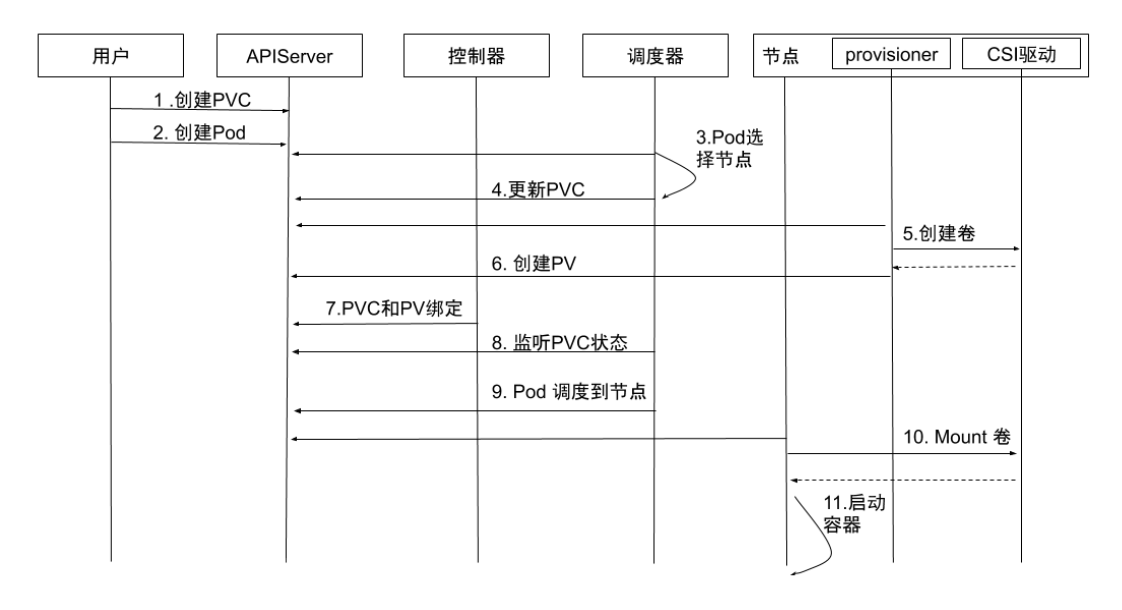
- 创建 PVC:用户创建 PVC,PVC 处于
pending状态 - 创建 Pod:用户创建 Pod
- Pod 选择节点:
kube-scheduler开始调度 Pod,通过 PVC 的pvc.spec.resources.requests.storage等选择满足条件的节点 - 更新 PVC:选择节点后,
kube-scheduler会给 PVC 添加包含节点信息的annotation: volume.kubernetes.io/selected-node:<节点名字> - 创建卷:运行在节点上的容器
external-provisioner监听到 PVC 带有该节点相关的annotation,向相应的 CSI 驱动申请分配卷 - 创建 PV:PVC 申请到所需的存储空间后,
external-provisioner创建 PV,该 PV 的pv.Spec.claimRef设置为对应的 PVC - PVC 和 PV 绑定:
kube-controller-manager将 PVC 和 PV 进行绑定,状态修改为Bound - 监听 PVC 状态:
kube-scheduler等待 PVC 编程Bound状态 - Pod 调度到节点:当 PVC 的状态为
Bound时,Pod 才算真正调度成功了。如果 PVC 一直处于Pending状态,超时后会再次进行调度 Mount卷:kubelet监听到有 Pod 已经调度到节点上,对本地存储进行mount操作- 启动容器:启动容器
Local Dynamic 的挑战
如果将磁盘空间作为一个存储池(例如 LVM)来动态分配,那么在分配出来的逻辑卷空间的使用上,可能会受到其他逻辑卷的 I/O 干扰,因为底层的物理卷可能是同一个。
如果 PV 后端的磁盘空间是一块独立的物理磁盘,则 I/O 就不会受到干扰。
生产实践经验分享
不同介质类型的磁盘,需要设置不同的
StorageClass,以便让用户做区分。StorageClass需要设置磁盘介质的类型,以便用户了解该类存储的属性。在本地存储的 PV 静态部署模式下,每个物理磁盘都尽量只创建一个 PV,而不是划分为多个分区来提供多个本地存储 PV,避免在使用时区分之间的
I/O干扰。本地存储需要配合磁盘检测来使用。当集群部署规模化后,每个集群的本地存储 PV 可能会超过几万个,如磁盘损坏将是频发事件。此时,需要在检测到磁盘损坏、丢盘等问题后,对节点的磁盘和相应的本地存储 PV 进行特定的处理,例如触发告警、自动
cordon节点、自动通知用户等。对于提供本地存储节点的磁盘管理,需要做到灵活管理和自动化。节点磁盘的信息可以归一、集中化管理。
在
local-volume-provisioner中增加部署逻辑,当容器运行起来时,拉取该节点需要提供本地存储的磁盘信息,例如磁盘的设备路径,以Filesystem或Block的模式提供本地存储,或者是否需要加入某个LVM的虚拟组(VG)等。local-volume-provisioner根据获取的磁盘信息对磁盘进行格式化,或者加入到某个VG,从而形成对本地存储支持的自动化闭环。
Rook
Rook 是一款云原生环境下的开源分布式存储编排系统,目前支持 Ceph、NFS、EdgeFS、Cassandra、CockroachDB 等存储系统。它实现了一个自动管理的、自动扩容的、自动修复的分布式存储服务。
Rook 支持自动部署、启动、配置、分配、扩容/缩容、升级、迁移、灾难恢复、监控以及资源管理。
Rook 架构
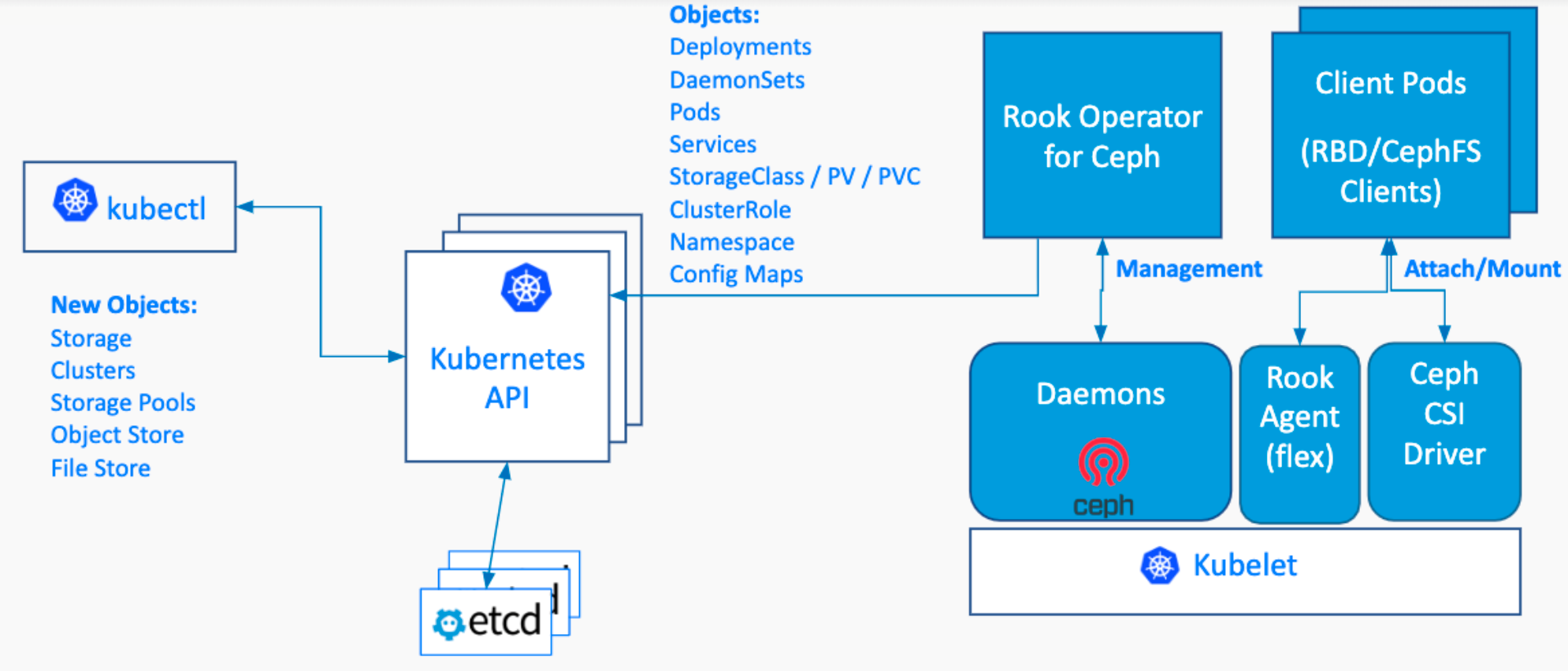
Rook Operator
Rook Operator 是 Rook 的大脑,以 deployment 形式存在。
其利用 Kubernetes 的 controller-runtime 框架实现了 CRD,并进而接受 Kubernetes 创建资源的请求并创建相关资源(集群,pool,块存储服务,文件存储服务等)
Rook Operator 监控存储守护进程,来确保存储集群的健康
监听 Rook Discovers 收集到的存储磁盘设备,并创建相应服务(Ceph 的话就是 OSD 了)
Rook Discover
Rook Discover 是以 DaemonSet 形式部署在所有的存储机上的,其检测挂接到存储节点上的存储设备。
把符合要求的存储设备记录下来,这样 Rook Operate 感知到以后就可以基于该存储设备创建相应服务了。例如使用 lsblk 罗列可用盘。
操作步骤
- Resetup rook,清除环境
1 | rm -rf /var/lib/rook |
- Add a new raw device,添加一块大于 5G 的盘
Create a raw disk from virtualbox console and attach to the vm (must > 5G).
- Clean env for next demo,清除资源,防止遗留
1 | delete ns rook-ceph |
- Checkout rook,下载代码
1 | git clone --single-branch --branch master https://github.com/rook/rook.git |
- Create rook operator,创建 operator
1 | crds.yaml # 注册控制器 |
可以修改控制器核心配置文件中的镜像文件地址,改成 aliyun 避免下面下镜像失败导致的问题
1 | # The default version of CSI supported by Rook will be started. To change the version |
1 | kubectl create -f crds.yaml -f common.yaml -f operator.yaml |
- Create ceph cluster,创建 ceph cluster
1 | kubectl get po -n rook-ceph |
Wait for all pod to be running, and:(这一步会下载很多镜像,容易出错),可以先通过 aliyun 下载,然后修改 tag
也可以直接修改 cm
1 | kubectl edit cm rook-ceph-operator-config |
1 | docker pull registry.aliyuncs.com/google_containers/csi-node-driver-registrar:v2.9.1 |
或者修改 yaml 配置中的镜像,将镜像前缀替换成 aliyun
1 | # 例如将 |
1 | kubectl create -f cluster-test.yaml |
整个过程会比较长,简单来说,就是
rook通过几个控制器检查独立的磁盘,并且使用ceph的命令行进行格式化处理1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31kubectl logs -f rook-ceph-osd-prepare-master-r5srp
2024-01-24 07:10:48.572868 I | cephosd: discovering hardware
2024-01-24 07:10:48.573130 D | exec: Running command: lsblk --all --noheadings --list --output KNAME
2024-01-24 07:10:48.582603 D | exec: Running command: lsblk /dev/fd0 --bytes --nodeps --pairs --paths --output SIZE,ROTA,RO,TYPE,PKNAME,NAME,KNAME,MOUNTPOINT,FSTYPE
// 依次处理每块磁盘
2024-01-24 07:10:49.182447 D | exec: Running command: lsblk /dev/sdb --bytes --nodeps --pairs --paths --output SIZE,ROTA,RO,TYPE,PKNAME,NAME,KNAME,MOUNTPOINT,FSTYPE
2024-01-24 07:10:49.188848 D | sys: lsblk output: "SIZE=\"10737418240\" ROTA=\"1\" RO=\"0\" TYPE=\"disk\" PKNAME=\"\" NAME=\"/dev/sdb\" KNAME=\"/dev/sdb\" MOUNTPOINT=\"\" FSTYPE=\"ceph_bluestore\""
2024-01-24 07:10:49.189049 D | exec: Running command: sgdisk --print /dev/sdb
2024-01-24 07:10:49.194088 D | exec: Running command: udevadm info --query=property /dev/sdb
2024-01-24 07:10:49.213747 D | sys: udevadm info output: "DEVLINKS=/dev/disk/by-path/pci-0000:00:10.0-scsi-0:0:1:0\nDEVNAME=/dev/sdb\nDEVPATH=/devices/pci0000:00/0000:00:10.0/host32/target32:0:1/32:0:1:0/block/sdb\nDEVTYPE=disk\nID_BUS=scsi\nID_FS_TYPE=ceph_bluestore\nID_FS_USAGE=other\nID_MODEL=VMware_Virtual_S\nID_MODEL_ENC=VMware\\x20Virtual\\x20S\nID_PATH=pci-0000:00:10.0-scsi-0:0:1:0\nID_PATH_TAG=pci-0000_00_10_0-scsi-0_0_1_0\nID_REVISION=1.0\nID_SCSI=1\nID_TYPE=disk\nID_VENDOR=VMware_\nID_VENDOR_ENC=VMware\\x2c\\x20\nMAJOR=8\nMINOR=16\nMPATH_SBIN_PATH=/sbin\nSCSI_MODEL=VMware_Virtual_S\nSCSI_MODEL_ENC=VMware\\x20Virtual\\x20S\nSCSI_REVISION=1.0\nSCSI_TPGS=0\nSCSI_TYPE=disk\nSCSI_VENDOR=VMware,\nSCSI_VENDOR_ENC=VMware,\\x20\nSUBSYSTEM=block\nTAGS=:systemd:\nUSEC_INITIALIZED=7881345425"
2024-01-24 07:10:49.213844 D | exec: Running command: lsblk --noheadings --path --list --output NAME /dev/sdb
2024-01-24 07:10:49.328153 D | inventory: &{Name:sdb Parent: HasChildren:false DevLinks:/dev/disk/by-path/pci-0000:00:10.0-scsi-0:0:1:0 Size:10737418240 UUID:fa8cb5e3-f65c-4a9e-8324-c3ab4696d8e8 Serial: Type:disk Rotational:true Readonly:false Partitions:[] Filesystem:ceph_bluestore Mountpoint: Vendor:VMware_ Model:VMware_Virtual_S WWN: WWNVendorExtension: Empty:false CephVolumeData: RealPath:/dev/sdb KernelName:sdb Encrypted:false}
2024-01-24 07:10:49.328235 D | cephosd: &{Name:sdb Parent: HasChildren:false DevLinks:/dev/disk/by-path/pci-0000:00:10.0-scsi-0:0:1:0 Size:10737418240 UUID:fa8cb5e3-f65c-4a9e-8324-c3ab4696d8e8 Serial: Type:disk Rotational:true Readonly:false Partitions:[] Filesystem:ceph_bluestore Mountpoint: Vendor:VMware_ Model:VMware_Virtual_S WWN: WWNVendorExtension: Empty:false CephVolumeData: RealPath:/dev/sdb KernelName:sdb Encrypted:false}
// 将新磁盘以 osd 加入进来
2024-01-24 07:10:53.357751 D | cephosd: {
"e4c5938e-0c71-4c89-bf03-c843aaeb042a": {
"ceph_fsid": "33f01f1f-49f5-4a3e-9e4d-170a78a73862",
"device": "/dev/sdb",
"osd_id": 1,
"osd_uuid": "e4c5938e-0c71-4c89-bf03-c843aaeb042a",
"type": "bluestore"
}
}
2024-01-24 07:10:53.357984 D | exec: Running command: lsblk /dev/sdb --bytes --nodeps --pairs --paths --output SIZE,ROTA,RO,TYPE,PKNAME,NAME,KNAME,MOUNTPOINT,FSTYPE
2024-01-24 07:10:53.365269 D | sys: lsblk output: "SIZE=\"10737418240\" ROTA=\"1\" RO=\"0\" TYPE=\"disk\" PKNAME=\"\" NAME=\"/dev/sdb\" KNAME=\"/dev/sdb\" MOUNTPOINT=\"\" FSTYPE=\"ceph_bluestore\""
2024-01-24 07:10:53.365582 D | exec: Running command: sgdisk --print /dev/sdb
2024-01-24 07:10:53.389306 I | cephosd: setting device class "hdd" for device "/dev/sdb"
2024-01-24 07:10:53.389338 I | cephosd: 1 ceph-volume raw osd devices configured on this node
2024-01-24 07:10:53.389378 I | cephosd: devices = [{ID:1 Cluster:ceph UUID:e4c5938e-0c71-4c89-bf03-c843aaeb042a DevicePartUUID: DeviceClass:hdd BlockPath:/dev/sdb MetadataPath: WalPath: SkipLVRelease:true Location:root=default host=master LVBackedPV:false CVMode:raw Store:bluestore TopologyAffinity: Encrypted:false ExportService:false NodeName: PVCName:}]Create storage class,等待 pod 都正常运行,创建 sc
1 | kubectl get po -n rook-ceph |
Wait for all pod to be running, and:
1 | kubectl create -f csi/rbd/storageclass-test.yaml |
- Check configuration,查看 cm 里面的配置
1 | kubectl get configmap -n rook-ceph rook-ceph-operator-config -oyaml |
- Check csidriver,查看 csidriver
1 | kubectl get csidriver rook-ceph.rbd.csi.ceph.com |
- Check csi plugin configuration,检查 cis 插件的配置
1 | kubectl get po csi-rbdplugin-j4s6c -n rook-ceph -oyaml |
plugin 直接使用主机上的 sock 进行管理
1 | ls /var/lib/kubelet/plugins/rook-ceph.rbd.csi.ceph.com/ |
- Create toolbox when required
1 | kubectl create -f toolbox.yaml |
可以启动一个操作 ceph 的 toolbox 容器
1 | kubectl exec -it rook-ceph-tools-66b77b8df5-x4lbt bash |
- Test networkstorage
1 | # cat pvc.yaml |
1 | # cat pod.yaml |
1 | kubectl create -f pvc.yaml |
- Enter pod and write some data
1 | # kubeclt exec -it task-pv-pod sh |
- Exit pod and delete the pod
1 | kubectl delete -f pod.yaml |
- Recreate the pod and check
/mnt/cephagain, and you will find the file is there
1 | kubectl create -f pod.yaml |
- Expose dashboard,修改
CephCluster,指定端口
1 | kubectl edit cephclusters.ceph.rook.io my-cluster |
由于 cephclusters 会检测 svc 变化,因此直接修改 svc 会被修改回来,因此需要额外使用一个 svc
1 | # kubectl create -f dashboard-external-https.yaml |
1 | # kubectl get svc rook-ceph-mgr-dashboard-external-https |
Login to the console with admin/<password>.
密码:
1 | kubectl -n rook-ceph get secret rook-ceph-dashboard-password -o jsonpath="{['data']['password']}" | base64 --decode && echo |

使用账号密码登录
- Clean up
1 | cd rook/cluster/examples/kubernetes/ceph |
- clean up
编辑下面四个文件,将 finalizer 的值修改为 null
例如
1 | finalizers: |
修改为
1 | finalizers:null |
执行下面循环,直至找不到任何rook关联对象。
1 | for i in `kubectl api-resources | grep true | awk '{print \$1}'`; do echo $i;kubectl get $i -n rook-ceph; done |
CSIDriver 发现
CSI 驱动发现:
如果一个 CSI 驱动创建 CSIDriver 对象,Kubernetes 用户可以通过 get CSIDriver 命令发现它们;
CSI 对象有如下特点:
- 自定义的 Kubernetes 逻辑
- Kubernetes 对存储卷有一系列操作,这些
CSIDriver可以自定义支持哪些操作?
Provisioner
CSI external-provisioner 是一个监控 Kubernetes PVC 对象的 Sidecar 容器。
当用户创建 PVC 后,Kubernetes 会监测 PVC 对应的 StorageClass,如果 StorageClass 中的 provisioner 与某插件匹配,该容器通过 CSI Endpoint(通常是 unix socket)调用 CreateVolume 方法。
如果 CreateVolume 方法调用成功,则 Provisioner sidecar 创建 Kubernetes PV 对象。
CSI External Provisioner
1 | # 基于 cephfs 的 plugin |
Provisioner 代码

Provisioner log
1 | # kubectl logs -f csi-rbdplugin-provisioner-77dd8f7f94-ssnf6 |
Rook Agent
Rook Agent 是以 DaemonSet 形式部署在所有的存储机上的,其处理所有的存储操作,例如挂卸载存储卷以及格式化文件系统等。
CSI 插件注册
1 | # kubectl get DaemonSet csi-rbdplugin -o yaml |
CSI Driver
1 | # kubectl get csidrivers.storage.k8s.io rook-ceph.rbd.csi.ceph.com -o yaml |
1 | ls /var/lib/kubelet/plugins/rook-ceph.rbd.csi.ceph.com/csi.sock |
1 | - args: |
Agent

Cluster
针对不同 ceph cluster,rook 启动一组管理组件,包括:
mon,mgr,osd,mds,rgw
1 | # kubectl get cephclusters.ceph.rook.io my-cluster -o yaml |
Pool
一个 ceph cluster 可以有多个 pool,定义副本数量,故障域等多个属性。
1 | # kubectl get cephblockpool replicapool -o yaml |
Storage Class
StorageClass 是 Kubernetes 用来自动创建 PV 的对象
1 | # kubectl get storageclasses.storage.k8s.io rook-ceph-block -o yaml |
References
Life of a Packet in Kubernetes — Part 1
Life of a Packet in Kubernetes — Part 2
扩展:Life of a Packet in Kubernetes — Part 3
扩展:Life of a Packet in Kubernetes — Part 4
扩展:Life of a Packet in ISTIO — Part 1