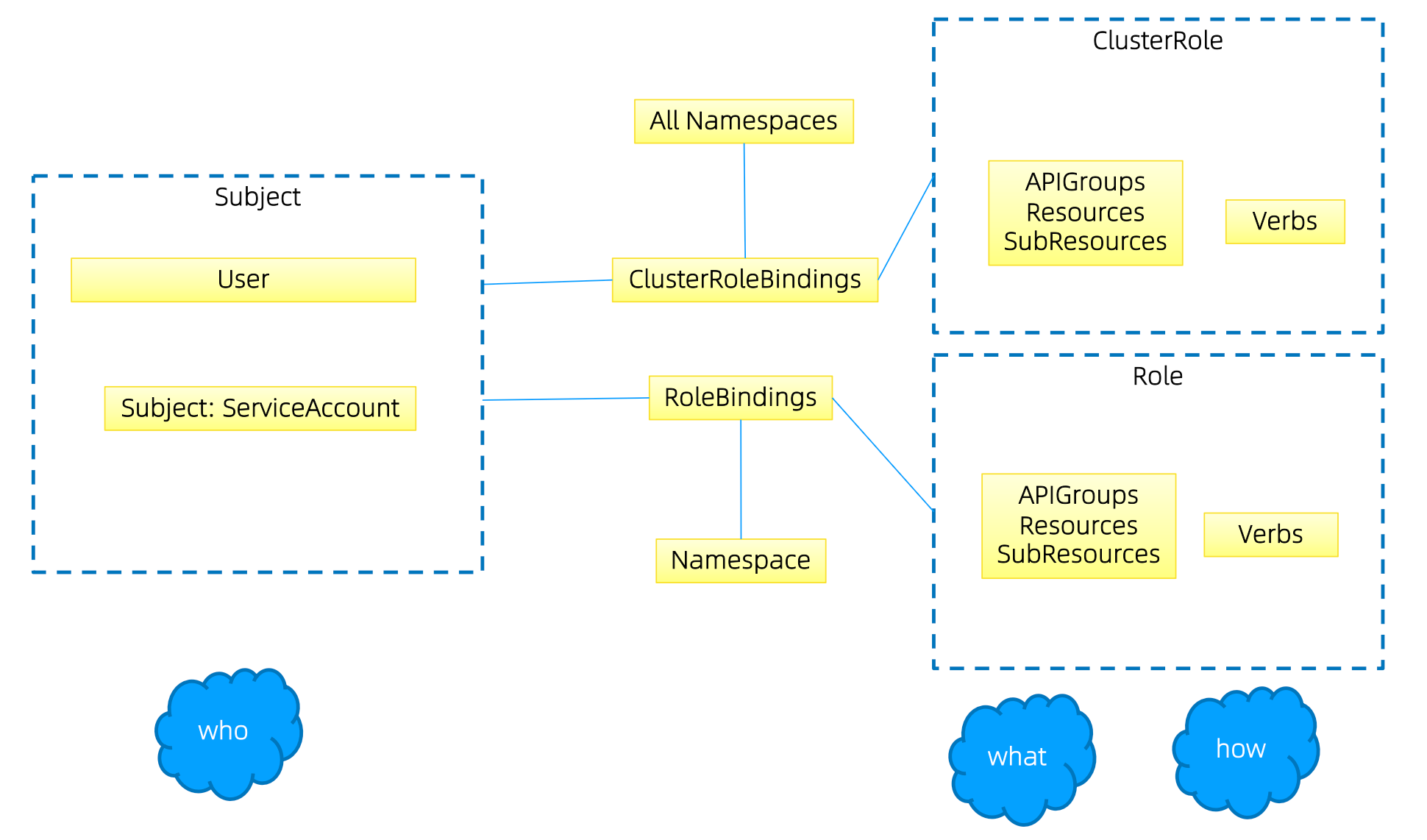
Role(角色)是一系列权限的集合,例如一个角色可以包含读取 Pod 的权限和列出 Pod 的权限。Role 只能用来给某个特定 Namespace 中的资源做鉴权,对多 Namespace 和集群级的资源或者是非资源类的 API(如 /heathz)使用 ClusterRole。
Role 示例
1 2 3 4 5 6 7 8 9
kind:Role apiVersion:rbac.authorization.k8s.io/v1 metadata: namespace:default name:pod-reader rules: -apiGroups: [""] # "" indicates the core API group resources: ["pods"] verbs: ["get", "watch", "list"]
ClusterRole 示例
1 2 3 4 5 6 7 8 9
kind:ClusterRole apiVersion:rbac.authorization.k8s.io/v1 metadata: # "namespace" omitted since ClusterRoles are not namespaced name:secret-reader rules: -apiGroups: [""] resources: ["secrets"] verbs: ["get", "watch", "list"]
binding
将用户和角色绑定起来
RoleBinding 示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14
# This role binding allows "dave" to read secrets in the "development" namespace. kind:RoleBinding apiVersion:rbac.authorization.k8s.io/v1 metadata: name:read-secrets namespace:development# This only grants permissions within the "development" namespace. subjects: -kind:User name:dave apiGroup:rbac.authorization.k8s.io roleRef: kind:ClusterRole name:secret-reader apiGroup:rbac.authorization.k8s.io
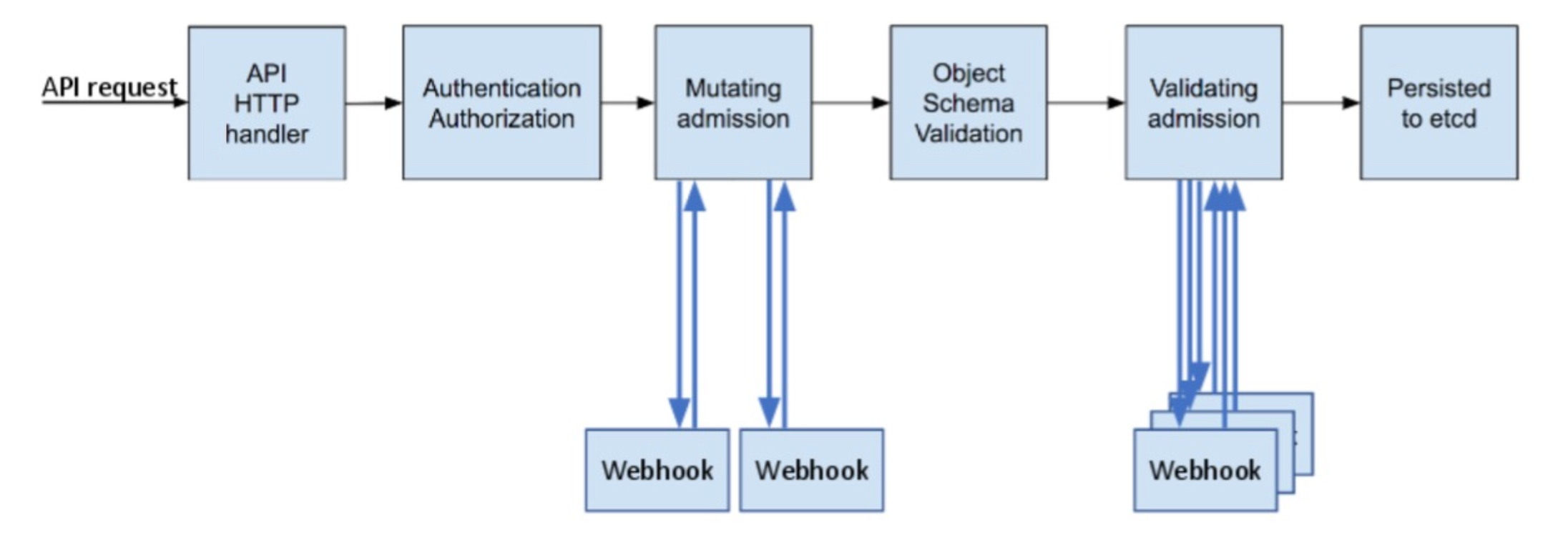
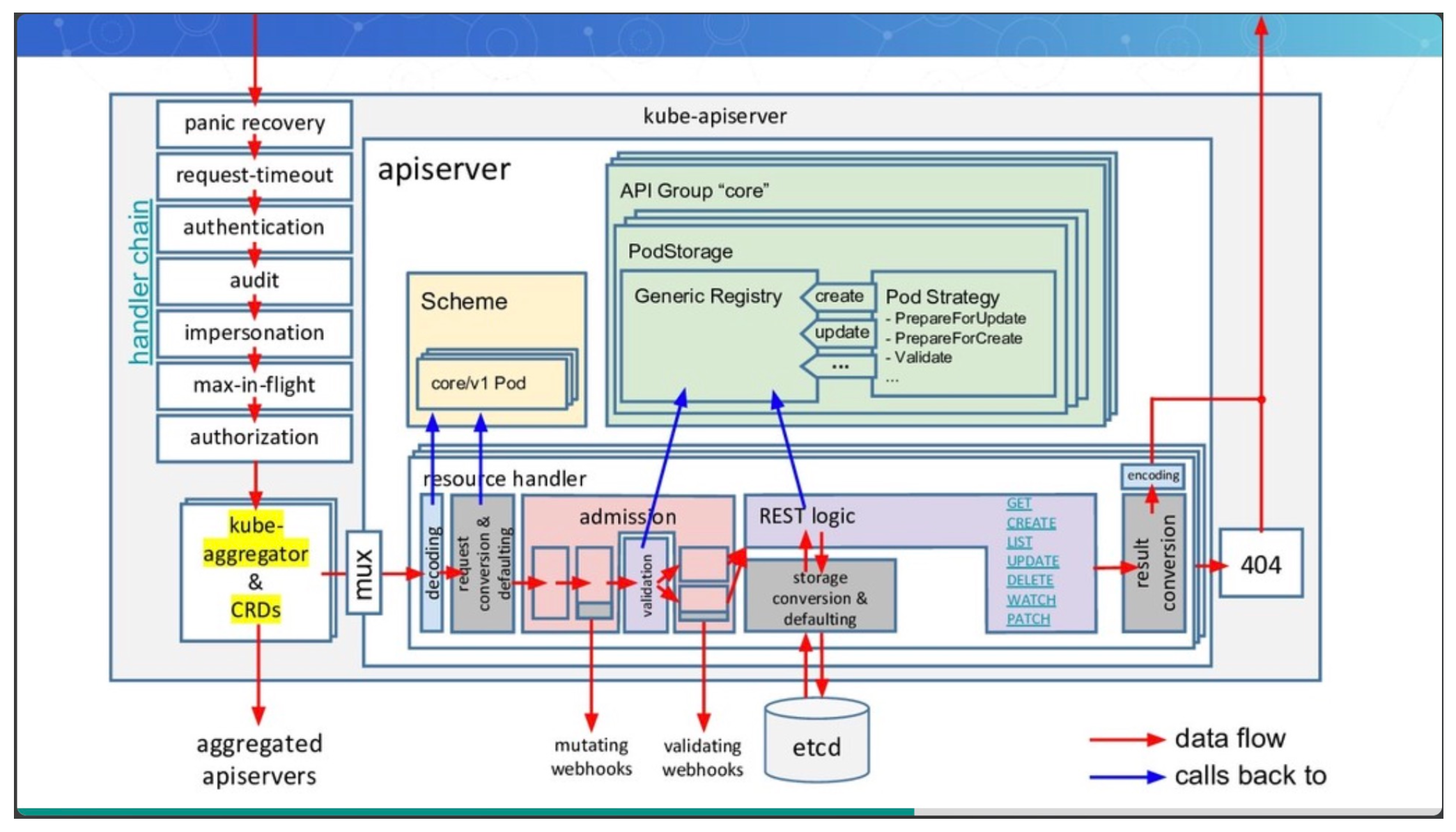
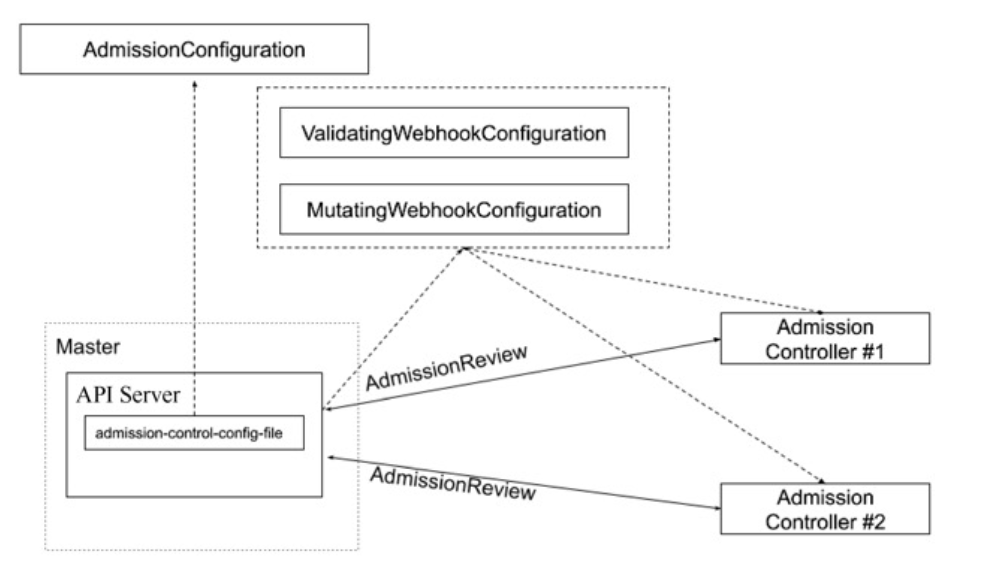
# kube-apiserver --help --admission-control strings Admission is divided into two phases. In the first phase, only mutating admission plugins run. In the second phase, only validating admission plugins run. The names in the below list may represent a validating plugin, a mutating plugin, or both. The order of plugins in which they are passed to this flag does not matter. Comma-delimited list of: AlwaysAdmit, AlwaysDeny, AlwaysPullImages, DefaultStorageClass, DefaultTolerationSeconds, DenyEscalatingExec, DenyExecOnPrivileged, EventRateLimit, ExtendedResourceToleration, ImagePolicyWebhook, LimitPodHardAntiAffinityTopology, LimitRanger, MutatingAdmissionWebhook, NamespaceAutoProvision, NamespaceExists, NamespaceLifecycle, NodeRestriction, OwnerReferencesPermissionEnforcement, PersistentVolumeClaimResize, PersistentVolumeLabel, PodNodeSelector, PodPreset, PodSecurityPolicy, PodTolerationRestriction, Priority, ResourceQuota, RuntimeClass, SecurityContextDeny, ServiceAccount, StorageObjectInUseProtection, TaintNodesByCondition, ValidatingAdmissionWebhook. (DEPRECATED: Use --enable-admission-plugins or --disable-admission-plugins instead. Will be removed in a future version.) --admission-control-config-file string File with admission control configuration. --disable-admission-plugins strings admission plugins that should be disabled although they are in the default enabled plugins list (NamespaceLifecycle, LimitRanger, ServiceAccount, TaintNodesByCondition, Priority, DefaultTolerationSeconds, DefaultStorageClass, StorageObjectInUseProtection, PersistentVolumeClaimResize, MutatingAdmissionWebhook, ValidatingAdmissionWebhook, RuntimeClass, ResourceQuota). Comma-delimited list of admission plugins: AlwaysAdmit, AlwaysDeny, AlwaysPullImages, DefaultStorageClass, DefaultTolerationSeconds, DenyEscalatingExec, DenyExecOnPrivileged, EventRateLimit, ExtendedResourceToleration, ImagePolicyWebhook, LimitPodHardAntiAffinityTopology, LimitRanger, MutatingAdmissionWebhook, NamespaceAutoProvision, NamespaceExists, NamespaceLifecycle, NodeRestriction, OwnerReferencesPermissionEnforcement, PersistentVolumeClaimResize, PersistentVolumeLabel, PodNodeSelector, PodPreset, PodSecurityPolicy, PodTolerationRestriction, Priority, ResourceQuota, RuntimeClass, SecurityContextDeny, ServiceAccount, StorageObjectInUseProtection, TaintNodesByCondition, ValidatingAdmissionWebhook. The order of plugins in this flag does not matter. --enable-admission-plugins strings admission plugins that should be enabled in addition to default enabled ones (NamespaceLifecycle, LimitRanger, ServiceAccount, TaintNodesByCondition, Priority, DefaultTolerationSeconds, DefaultStorageClass, StorageObjectInUseProtection, PersistentVolumeClaimResize, MutatingAdmissionWebhook, ValidatingAdmissionWebhook, RuntimeClass, ResourceQuota). Comma-delimited list of admission plugins: AlwaysAdmit, AlwaysDeny, AlwaysPullImages, DefaultStorageClass, DefaultTolerationSeconds, DenyEscalatingExec, DenyExecOnPrivileged, EventRateLimit, ExtendedResourceToleration, ImagePolicyWebhook, LimitPodHardAntiAffinityTopology, LimitRanger, MutatingAdmissionWebhook, NamespaceAutoProvision, NamespaceExists, NamespaceLifecycle, NodeRestriction, OwnerReferencesPermissionEnforcement, PersistentVolumeClaimResize, PersistentVolumeLabel, PodNodeSelector, PodPreset, PodSecurityPolicy, PodTolerationRestriction, Priority, ResourceQuota, RuntimeClass, SecurityContextDeny, ServiceAccount, StorageObjectInUseProtection, TaintNodesByCondition, ValidatingAdmissionWebhook. The order of plugins in this flag does not matter.
// WithMaxInFlightLimit limits the number of in-flight requests to buffer size of the passed in channel. funcWithMaxInFlightLimit( handler http.Handler, nonMutatingLimit int, mutatingLimit int, longRunningRequestCheck apirequest.LongRunningRequestCheck, ) http.Handler { if nonMutatingLimit == 0 && mutatingLimit == 0 { return handler } var nonMutatingChan chanbool var mutatingChan chanbool if nonMutatingLimit != 0 { nonMutatingChan = make(chanbool, nonMutatingLimit) klog.V(2).InfoS("Initialized nonMutatingChan", "len", nonMutatingLimit) } else { klog.V(2).InfoS("Running with nil nonMutatingChan") } if mutatingLimit != 0 { mutatingChan = make(chanbool, mutatingLimit) klog.V(2).InfoS("Initialized mutatingChan", "len", mutatingLimit) } else { klog.V(2).InfoS("Running with nil mutatingChan") } initMaxInFlight(nonMutatingLimit, mutatingLimit)
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) { ctx := r.Context() requestInfo, ok := apirequest.RequestInfoFrom(ctx) if !ok { handleError(w, r, fmt.Errorf("no RequestInfo found in context, handler chain must be wrong")) return }
// Skip tracking long running events. if longRunningRequestCheck != nil && longRunningRequestCheck(r, requestInfo) { handler.ServeHTTP(w, r) return }
var c chanbool isMutatingRequest := !nonMutatingRequestVerbs.Has(requestInfo.Verb) if isMutatingRequest { c = mutatingChan } else { c = nonMutatingChan }
if c == nil { handler.ServeHTTP(w, r) } else {
select { case c <- true: // We note the concurrency level both while the // request is being served and after it is done being // served, because both states contribute to the // sampled stats on concurrency. if isMutatingRequest { watermark.recordMutating(len(c)) } else { watermark.recordReadOnly(len(c)) } deferfunc() { <-c if isMutatingRequest { watermark.recordMutating(len(c)) } else { watermark.recordReadOnly(len(c)) } }() handler.ServeHTTP(w, r)
default: // at this point we're about to return a 429, BUT not all actors should be rate limited. A system:master is so powerful // that they should always get an answer. It's a super-admin or a loopback connection. if currUser, ok := apirequest.UserFrom(ctx); ok { for _, group := range currUser.GetGroups() { if group == user.SystemPrivilegedGroup { handler.ServeHTTP(w, r) return } } } // We need to split this data between buckets used for throttling. metrics.RecordDroppedRequest(r, requestInfo, metrics.APIServerComponent, isMutatingRequest) metrics.RecordRequestTermination(r, requestInfo, metrics.APIServerComponent, http.StatusTooManyRequests) tooManyRequests(r, w, retryAfter) } } }) }
# kubectl get apiservices.apiregistration.k8s.io NAME SERVICE AVAILABLE AGE v1. Local True 76m v1.admissionregistration.k8s.io Local True 76m v1.apiextensions.k8s.io Local True 76m v1.apps Local True 76m v1.authentication.k8s.io Local True 76m v1.authorization.k8s.io Local True 76m v1.autoscaling Local True 76m v1.batch Local True 76m v1.certificates.k8s.io Local True 76m v1.coordination.k8s.io Local True 76m v1.discovery.k8s.io Local True 76m v1.events.k8s.io Local True 76m v1.flowcontrol.apiserver.k8s.io Local True 76m v1.networking.k8s.io Local True 76m v1.node.k8s.io Local True 76m v1.policy Local True 76m v1.rbac.authorization.k8s.io Local True 76m v1.scheduling.k8s.io Local True 76m v1.storage.k8s.io Local True 76m v1beta3.flowcontrol.apiserver.k8s.io Local True 76m v2.autoscaling Local True 76m
// GroupName is the group name use in this package const GroupName = "testapigroup.apimachinery.k8s.io"
// SchemeGroupVersion is group version used to register these objects var SchemeGroupVersion = schema.GroupVersion{Group: GroupName, Version: runtime.APIVersionInternal}
// Kind takes an unqualified kind and returns a Group qualified GroupKind funcKind(kind string) schema.GroupKind { return SchemeGroupVersion.WithKind(kind).GroupKind() }
// Resource takes an unqualified resource and returns a Group qualified GroupResource funcResource(resource string) schema.GroupResource { return SchemeGroupVersion.WithResource(resource).GroupResource() }
// 将对象加入SchemeBuild // Adds the list of known types to the given scheme. funcaddKnownTypes(scheme *runtime.Scheme)error { scheme.AddKnownTypes(SchemeGroupVersion, &Carp{}, ) returnnil }
// Node is a worker node in Kubernetes. // Each node will have a unique identifier in the cache (i.e. in etcd). type Node struct { metav1.TypeMeta `json:",inline"` // Standard object's metadata. // More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#metadata // +optional metav1.ObjectMeta `json:"metadata,omitempty" protobuf:"bytes,1,opt,name=metadata"`
// Spec defines the behavior of a node. // https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#spec-and-status // +optional Spec NodeSpec `json:"spec,omitempty" protobuf:"bytes,2,opt,name=spec"`
// Most recently observed status of the node. // Populated by the system. // Read-only. // More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#spec-and-status // +optional Status NodeStatus `json:"status,omitempty" protobuf:"bytes,3,opt,name=status"` }
// TypeMeta describes an individual object in an API response or request // with strings representing the type of the object and its API schema version. // Structures that are versioned or persisted should inline TypeMeta. // // +k8s:deepcopy-gen=false type TypeMeta struct { // Kind is a string value representing the REST resource this object represents. // Servers may infer this from the endpoint the client submits requests to. // Cannot be updated. // In CamelCase. // More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#types-kinds // +optional Kind string`json:"kind,omitempty" protobuf:"bytes,1,opt,name=kind"`
// APIVersion defines the versioned schema of this representation of an object. // Servers should convert recognized schemas to the latest internal value, and // may reject unrecognized values. // More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#resources // +optional APIVersion string`json:"apiVersion,omitempty" protobuf:"bytes,2,opt,name=apiVersion"` }
// Strategy is the default logic that applies when creating and updating ConfigMap // objects via the REST API. var Strategy = strategy{legacyscheme.Scheme, names.SimpleNameGenerator}
// ValidateConfigMapUpdate tests if required fields in the ConfigMap are set. funcValidateConfigMapUpdate(newCfg, oldCfg *core.ConfigMap) field.ErrorList { allErrs := field.ErrorList{} allErrs = append(allErrs, ValidateObjectMetaUpdate(&newCfg.ObjectMeta, &oldCfg.ObjectMeta, field.NewPath("metadata"))...)
if oldCfg.Immutable != nil && *oldCfg.Immutable { if newCfg.Immutable == nil || !*newCfg.Immutable { allErrs = append(allErrs, field.Forbidden(field.NewPath("immutable"), "field is immutable when `immutable` is set")) } if !reflect.DeepEqual(newCfg.Data, oldCfg.Data) { allErrs = append(allErrs, field.Forbidden(field.NewPath("data"), "field is immutable when `immutable` is set")) } if !reflect.DeepEqual(newCfg.BinaryData, oldCfg.BinaryData) { allErrs = append(allErrs, field.Forbidden(field.NewPath("binaryData"), "field is immutable when `immutable` is set")) } }
// don't allow the pods/status endpoint to touch owner references since old kubelets corrupt them in a way // that breaks garbage collection newPod.OwnerReferences = oldPod.OwnerReferences }
当更新 Pod 的 status 时,将所有的 spec 部分丢弃。作用是更新时将 spec 对象和 status 对象分离,更新这部分,则丢弃另外一部分的更新,避免冲突。